Сортинг это: Недопустимое название — Циклопедия
Всё о сортировке в Python: исчерпывающий гайд
Сортировка в Python выполняется функцией sorted(), если это итерируемые объекты, и методом list.sort(), если это список. Рассмотрим подробнее, как это работало в старых версиях и как работает сейчас.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
1
Основы сортировки
Для сортировки по возрастанию достаточно вызвать функцию сортировки Python sorted(), которая вернёт новый отсортированный список:
>>> sorted([5, 2, 3, 1, 4])
[1, 2, 3, 4, 5]Также можно использовать метод списков list.sort(), который изменяет исходный список (и возвращает None во избежание путаницы). Обычно это не так удобно, как использование sorted(), но если вам не нужен исходный список, то так будет немного эффективнее:
>>> a = [5, 2, 3, 1, 4]
>>> a.sort()
>>> a
[1, 2, 3, 4, 5] перев. В Python вернуть
перев. В Python вернуть None и не вернуть ничего — одно и то же.Ещё одно отличие заключается в том, что метод list.sort() определён только для списков, в то время как sorted() работает со всеми итерируемыми объектами:
>>> sorted({1: 'D', 2: 'B', 3: 'B', 4: 'E', 5: 'A'})
[1, 2, 3, 4, 5]Прим.перев. При итерировании по словарю Python возвращает его ключи. Если вам нужны их значения или пары «ключ-значение», используйте методы dict.values() и dict.items() соответственно.
Рассмотрим основные функции сортировки Python.
2
Функции-ключи
С версии Python 2.4 у list.sort() и sorted() появился параметр key для указания функции, которая будет вызываться на каждом элементе до сравнения. Вот регистронезависимое сравнение строк:
>>> sorted("This is a test string from Andrew".split(), key=str.lower)
['a', 'Andrew', 'from', 'is', 'string', 'test', 'This']Значение key должно быть функцией, принимающей один аргумент и возвращающей ключ для сортировки. Работает быстро, потому что функция-ключ вызывается один раз для каждого элемента.
Работает быстро, потому что функция-ключ вызывается один раз для каждого элемента.
Часто можно встретить код, где сложный объект сортируется по одному из его индексов. Например:
>>> student_tuples = [
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
]
>>> sorted(student_tuples, key=lambda student: student[2]) # сортируем по возрасту
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]Тот же метод работает для объектов с именованными атрибутами:
>>> class Student:
def __init__(self, name, grade, age):
self.name = name
self.grade = grade
self.age = age
def __repr__(self):
return repr((self.name, self.grade, self.age))
def weighted_grade(self):
return 'CBA'.index(self.grade) / self.age
>>> student_objects = [
Student('john', 'A', 15),
Student('jane', 'B', 12),
Student('dave', 'B', 10),
]
>>> sorted(student_objects, key=lambda student: student.

3
Функции модуля operator
Показанные выше примеры функций-ключей встречаются настолько часто, что Python предлагает удобные функции, чтобы сделать всё проще и быстрее. Модуль operator содержит функции itemgetter()
, attrgetter() и, начиная с Python 2.6, methodcaller(). С ними всё ещё проще:
>>> from operator import itemgetter, attrgetter, methodcaller
>>> sorted(student_tuples, key=itemgetter(2))
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
>>> sorted(student_objects, key=attrgetter('age'))
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]Функции operator дают возможность использовать множественные уровни сортировки в Python. Отсортируем учеников сначала по оценке, а затем по возрасту:
>>> sorted(student_tuples, key=itemgetter(1, 2))
[('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)]
>>> sorted(student_objects, key=attrgetter('grade', 'age'))
[('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)]Используем функцию methodcaller() для сортировки учеников по взвешенной оценке:
>>> [(student. name, student.weighted_grade()) for student in student_objects]
[('john', 0.13333333333333333), ('jane', 0.08333333333333333), ('dave', 0.1)]
>>> sorted(student_objects, key=methodcaller('weighted_grade'))
[('jane', 'B', 12), ('dave', 'B', 10), ('john', 'A', 15)] name, student.weighted_grade()) for student in student_objects]
[('john', 0.13333333333333333), ('jane', 0.08333333333333333), ('dave', 0.1)]
>>> sorted(student_objects, key=methodcaller('weighted_grade'))
[('jane', 'B', 12), ('dave', 'B', 10), ('john', 'A', 15)]
name, student.weighted_grade()) for student in student_objects]
[('john', 0.13333333333333333), ('jane', 0.08333333333333333), ('dave', 0.1)]
>>> sorted(student_objects, key=methodcaller('weighted_grade'))
[('jane', 'B', 12), ('dave', 'B', 10), ('john', 'A', 15)]4
Сортировка по возрастанию и сортировка по убыванию в Python
У list.sort() и sorted() есть параметр reverse, принимающий boolean-значение. Он нужен для обозначения сортировки по убыванию. Отсортируем учеников по убыванию возраста:
>>> sorted(student_tuples, key=itemgetter(2), reverse=True)
[('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
>>> sorted(student_objects, key=attrgetter('age'), reverse=True)
[('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]5
Стабильность сортировки и сложные сортировки в Python
Начиная с версии Python 2.2, сортировки гарантированно стабильны: если у нескольких записей есть одинаковые ключи, их порядок останется прежним.
Пример:
>>> data = [('red', 1), ('blue', 1), ('red', 2), ('blue', 2)]
>>> sorted(data, key=itemgetter(0))
[('blue', 1), ('blue', 2), ('red', 1), ('red', 2)]Обратите внимание, что две записи с 'blue' сохранили начальный порядок. Это свойство позволяет составлять сложные сортировки путём постепенных сортировок. Далее мы сортируем данные учеников сначала по возрасту в порядке возрастания, а затем по оценкам в убывающем порядке, чтобы получить данные, отсортированные в первую очередь по оценке и во вторую — по возрасту:
>>> s = sorted(student_objects, key=attrgetter('age')) # сортируем по вторичному ключу >>> sorted(s, key=attrgetter('grade'), reverse=True) # по первичному [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]>>> a = [5, 2, 3, 1, 4] >>> a.sort() >>> a [1, 2, 3, 4, 5]>>> sorted({1: 'D', 2: 'B', 3: 'B', 4: 'E', 5: 'A'}) [1, 2, 3, 4, 5]
Алгоритмы сортировки Python вроде Timsort проводят множественные сортировки так эффективно, потому что может извлечь пользу из любого порядка, уже присутствующего в наборе данных.
6
Декорируем-сортируем-раздекорируем
- Сначала исходный список пополняется новыми значениями, контролирующими порядок сортировки.
- Затем новый список сортируется.
- После этого добавленные значения убираются, и в итоге остаётся отсортированный список, содержащий только исходные элементы.
Вот так можно отсортировать данные учеников по оценке:
>>> decorated = [(student.grade, i, student) for i, student in enumerate(student_objects)] >>> decorated.sort() >>> [student for grade, i, student in decorated] # раздекорируем [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]>>> sorted("This is a test string from Andrew".split(), key=str.lower) ['a', 'Andrew', 'from', 'is', 'string', 'test', 'This']
Это работает из-за того, что кортежи сравниваются лексикографически, сравниваются первые элементы, а если они совпадают, то сравниваются вторые и так далее.
Не всегда обязательно включать индекс в декорируемый список, но у него есть преимущества:
- Сортировка стабильна — если у двух элементов одинаковый ключ, то их порядок не изменится.
- У исходных элементов не обязательно должна быть возможность сравнения, так как порядок декорированных кортежей будет определяться максимум по первым двум элементам. Например, исходный список может содержать комплексные числа, которые нельзя сравнивать напрямую.

Ещё эта идиома называется преобразованием Шварца в честь Рэндела Шварца, который популяризировал её среди Perl-программистов.
Для больших списков и версий Python ниже 2.4, «декорируем-сортируем-раздекорируем» будет оптимальным способом сортировки. Для версий 2.4+ ту же функциональность предоставляют функции-ключи.
7
Использование параметра cmp
Все версии Python 2.x поддерживали параметр cmp для обработки пользовательских функций сравнения. В Python 3.0 от этого параметра полностью избавились. В Python 2.x в sort() можно было передать функцию, которая использовалась бы для сравнения элементов. Она должна принимать два аргумента и возвращать отрицательное значение для случая «меньше чем», положительное — для «больше чем» и ноль, если они равны:
>>> def numeric_compare(x, y):
return x - y
>>> sorted([5, 2, 4, 1, 3], cmp=numeric_compare)
[1, 2, 3, 4, 5]Можно сравнивать в обратном порядке:
>>> def reverse_numeric(x, y):
return y - x
>>> sorted([5, 2, 4, 1, 3], cmp=reverse_numeric)
[5, 4, 3, 2, 1]При портировании кода с версии 2.
x на 3.x может возникнуть ситуация, когда нужно преобразовать пользовательскую функцию для сравнения в функцию-ключ. Следующая обёртка упрощает эту задачу:
def cmp_to_key(mycmp): 'Перевести cmp=функция в key=функция' class K(object): def __init__(self, obj, *args): self.obj = obj def __lt__(self, other): return mycmp(self.obj, other.obj) < 0 def __gt__(self, other): return mycmp(self.obj, other.obj) > 0 def __eq__(self, other): return mycmp(self.obj, other.obj) == 0 def __le__(self, other): return mycmp(self.obj, other.obj) <= 0 def __ge__(self, other): return mycmp(self.obj, other.obj) >= 0 def __ne__(self, other): return mycmp(self.obj, other.obj) != 0 return K>>> from operator import itemgetter, attrgetter, methodcaller >>> sorted(student_tuples, key=itemgetter(2)) [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)] >>> sorted(student_objects, key=attrgetter('age')) [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
Чтобы произвести преобразование, оберните старую функцию:
>>> sorted([5, 2, 4, 1, 3], key=cmp_to_key(reverse_numeric))
[5, 4, 3, 2, 1]В Python 2. 7 функция
7 функция cmp_to_key() была добавлена в модуль functools.
8
Поддержание порядка сортировки
В стандартной библиотеке Python нет модулей, аналогичных типам данных C++ вроде set и map. Python делегирует эту задачу сторонним библиотекам, доступным в Python Package Index: они используют различные методы для сохранения типов list, dict и set в отсортированном порядке. Поддержание порядка с помощью специальной структуры данных может помочь избежать очень медленного поведения (квадратичного времени выполнения) при наивном подходе с редактированием и постоянной пересортировкой данных. Вот некоторые из модулей, реализующих эти типы данных:
- SortedContainers — реализация сортированных типов
list,dictиsetна чистом Python, по скорости не уступает реализациям на C. Тестирование включает 100% покрытие кода и многие часы стресс-тестирования. В документации можно найти полный справочник по API, сравнение производительности и руководства по внесению своего вклада. - rbtree — быстрая реализация на C для типов
dictиset. Реализация использует структуру данных, известную как красно-чёрное дерево. - treap — сортированный
dict. В реализации используется Декартово дерево, а производительность улучшена с помощью Cython. - bintrees — несколько реализаций типов
dictиsetна основе деревьев на C. Самые быстрые основаны на АВЛ и красно-чёрных деревьях. Расширяет общепринятый API для предоставления операций множеств для словарей. - banyan — быстрая реализация
dictиsetна C. - skiplistcollections — реализация на чистом Python, основанная на списках с пропусками, предлагает ограниченный API для типов
dictиset. - blist — предоставляет сортированные типы
list,dictиset, основанные на типе данных «blist», реализация на Б-деревьях. Написано на Python и C.

9
Прочее
Для сортировки с учётом языка используйте locale. в качестве ключевой функции или  strxfrm()
strxfrm()locale.strcoll() в качестве функции сравнения. Параметр reverse всё ещё сохраняет стабильность сортировки. Этот эффект можно сымитировать без параметра, использовав встроенную функцию reversed() дважды:
>>> data = [('red', 1), ('blue', 1), ('red', 2), ('blue', 2)]
>>> assert sorted(data, reverse=True) == list(reversed(sorted(reversed(data))))Чтобы создать стандартный порядок сортировки для класса, просто добавьте реализацию соответствующих методов сравнения:
>>> Student.__eq__ = lambda self, other: self.age == other.age
>>> Student.__ne__ = lambda self, other: self.age != other.age
>>> Student.__lt__ = lambda self, other: self.age < other.age
>>> Student.__le__ = lambda self, other: self.age <= other.age
>>> Student.__gt__ = lambda self, other: self.age > other. age
>>> Student.__ge__ = lambda self, other: self.age >= other.age
>>> sorted(student_objects)
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)] age
>>> Student.__ge__ = lambda self, other: self.age >= other.age
>>> sorted(student_objects)
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
age
>>> Student.__ge__ = lambda self, other: self.age >= other.age
>>> sorted(student_objects)
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]Для типов, сравнение которых работает обычным образом, рекомендуется определять все 6 операторов. Декоратор классов functools.total_ordering упрощает их реализацию. Функциям-ключам не нужен доступ к внутренним данным сортируемых объектов. Они также могут осуществлять доступ к внешним ресурсам. Например, если оценки ученика хранятся в словаре, их можно использовать для сортировки отдельного списка с именами учеников:
>>> students = ['dave', 'john', 'jane']
>>> newgrades = {'john': 'F', 'jane':'A', 'dave': 'C'}
>>> sorted(students, key=newgrades.__getitem__)
['jane', 'dave', 'john']
Вас также может заинтересовать статьи:
Перевод статьи «Sorting Mini-HOW TO»
Array.prototype.
 sort() — JavaScript | MDN
sort() — JavaScript | MDN
Метод sort() на месте сортирует элементы массива и возвращает отсортированный массив. Сортировка не обязательно устойчива (англ.). Порядок сортировки по умолчанию соответствует порядку кодовых точек Unicode.
arr.sort([compareFunction])Параметры
compareFunction- Необязательный параметр. Указывает функцию, определяющую порядок сортировки. Если опущен, массив сортируется в соответствии со значениями кодовых точек каждого символа Unicode, полученных путём преобразования каждого элемента в строку.
Возвращаемое значение
Отсортированный массив. Важно, что копия массива не создаётся — массив сортируется на месте.
Если функция сравнения compareFunction не предоставляется, элементы сортируются путём преобразования их в строки и сравнения строк в порядке следования кодовых точек Unicode. Например, слово «Вишня» идёт перед словом «бананы». При числовой сортировке, 9 идёт перед 80, но поскольку числа преобразуются в строки, то «80» идёт перед «9» в соответствии с порядком в Unicode.
При числовой сортировке, 9 идёт перед 80, но поскольку числа преобразуются в строки, то «80» идёт перед «9» в соответствии с порядком в Unicode.
var fruit = ['арбузы', 'бананы', 'Вишня'];
fruit.sort();
var scores = [1, 2, 10, 21];
scores.sort();
var things = ['слово', 'Слово', '1 Слово', '2 Слова'];
things.sort();
Если функция сравнения compareFunction предоставлена, элементы массива сортируются в соответствии с её возвращаемым значением. Если сравниваются два элемента a и b, то:
- Если
compareFunction(a, b)меньше 0, сортировка поставитaпо меньшему индексу, чемb, то есть,aидёт первым. - Если
compareFunction(a, b)вернёт 0, сортировка оставитaиbнеизменными по отношению друг к другу, но отсортирует их по отношению ко всем другим элементам. Обратите внимание: стандарт ECMAscript не гарантирует данное поведение, и ему следуют не все браузеры (например, версии Mozilla по крайней мере, до 2003 года). - Если
compareFunction(a, b)больше 0, сортировка поставитbпо меньшему индексу, чемa. - Функция
compareFunction(a, b)должна всегда возвращать одинаковое значение для определённой пары элементовaиb. Если будут возвращаться непоследовательные результаты, порядок сортировки будет не определён.

Итак, функция сравнения имеет следующую форму:
function compare(a, b) {
if (a меньше b по некоторому критерию сортировки) {
return -1;
}
if (a больше b по некоторому критерию сортировки) {
return 1;
}
return 0;
}
Для числового сравнения, вместо строкового, функция сравнения может просто вычитать b из a. Следующая функция будет сортировать массив по возрастанию:
function compareNumbers(a, b) {
return a - b;
}
Метод sort можно удобно использовать с функциональными выражениями (и замыканиями):
var numbers = [4, 2, 5, 1, 3];
numbers. sort(function(a, b) {
return a - b;
});
console.log(numbers);
 sort(function(a, b) {
return a - b;
});
console.log(numbers);
sort(function(a, b) {
return a - b;
});
console.log(numbers);
Объекты могут быть отсортированы по значению одного из своих свойств.
var items = [
{ name: 'Edward', value: 21 },
{ name: 'Sharpe', value: 37 },
{ name: 'And', value: 45 },
{ name: 'The', value: -12 },
{ name: 'Magnetic' },
{ name: 'Zeros', value: 37 }
];
items.sort(function (a, b) {
if (a.name > b.name) {
return 1;
}
if (a.name < b.name) {
return -1;
}
return 0;
});
Пример: создание, отображение и сортировка массива
В следующем примере создаётся четыре массива, сначала отображается первоначальный массив, а затем они сортируются. Числовые массивы сортируются сначала без, а потом с функцией сравнения.
var stringArray = ['Голубая', 'Горбатая', 'Белуга'];
var numericStringArray = ['80', '9', '700'];
var numberArray = [40, 1, 5, 200];
var mixedNumericArray = ['80', '9', '700', 40, 1, 5, 200];
function compareNumbers(a, b) {
return a - b;
}
console. log('stringArray:', stringArray.join());
console.log('Сортировка:', stringArray.sort());
console.log('numberArray:', numberArray.join());
console.log('Сортировка без функции сравнения:', numberArray.sort());
console.log('Сортировка с функцией compareNumbers:', numberArray.sort(compareNumbers));
console.log('numericStringArray:', numericStringArray.join());
console.log('Сортировка без функции сравнения:', numericStringArray.sort());
console.log('Сортировка с функцией compareNumbers:', numericStringArray.sort(compareNumbers));
console.log('mixedNumericArray:', mixedNumericArray.join());
console.log('Сортировка без функции сравнения:', mixedNumericArray.sort());
console.log('Сортировка с функцией compareNumbers:', mixedNumericArray.sort(compareNumbers));
 log('stringArray:', stringArray.join());
console.log('Сортировка:', stringArray.sort());
console.log('numberArray:', numberArray.join());
console.log('Сортировка без функции сравнения:', numberArray.sort());
console.log('Сортировка с функцией compareNumbers:', numberArray.sort(compareNumbers));
console.log('numericStringArray:', numericStringArray.join());
console.log('Сортировка без функции сравнения:', numericStringArray.sort());
console.log('Сортировка с функцией compareNumbers:', numericStringArray.sort(compareNumbers));
console.log('mixedNumericArray:', mixedNumericArray.join());
console.log('Сортировка без функции сравнения:', mixedNumericArray.sort());
console.log('Сортировка с функцией compareNumbers:', mixedNumericArray.sort(compareNumbers));
log('stringArray:', stringArray.join());
console.log('Сортировка:', stringArray.sort());
console.log('numberArray:', numberArray.join());
console.log('Сортировка без функции сравнения:', numberArray.sort());
console.log('Сортировка с функцией compareNumbers:', numberArray.sort(compareNumbers));
console.log('numericStringArray:', numericStringArray.join());
console.log('Сортировка без функции сравнения:', numericStringArray.sort());
console.log('Сортировка с функцией compareNumbers:', numericStringArray.sort(compareNumbers));
console.log('mixedNumericArray:', mixedNumericArray.join());
console.log('Сортировка без функции сравнения:', mixedNumericArray.sort());
console.log('Сортировка с функцией compareNumbers:', mixedNumericArray.sort(compareNumbers));
Этот пример произведёт следующий вывод. Как показывает вывод, когда используется функция сравнения, числа сортируются корректно вне зависимости от того, являются ли они собственно числами или строками с числами.
stringArray: Голубая,Горбатая,Белуга Сортировка: Белуга,Голубая,Горбатая numberArray: 40,1,5,200 Сортировка без функции сравнения: 1,200,40,5 Сортировка с функцией compareNumbers: 1,5,40,200 numericStringArray: 80,9,700 Сортировка без функции сравнения: 700,80,9 Сортировка с функцией compareNumbers: 9,80,700 mixedNumericArray: 80,9,700,40,1,5,200 Сортировка без функции сравнения: 1,200,40,5,700,80,9 Сортировка с функцией compareNumbers: 1,5,9,40,80,200,700
Пример: сортировка не-ASCII символов
Для сортировки строк с не-ASCII символами, то есть строк с символами акцента (e, é, è, a, ä и т. д.), строк, с языками, отличными от английского: используйте
д.), строк, с языками, отличными от английского: используйте String.localeCompare. Эта функция может сравнивать эти символы, чтобы они становились в правильном порядке.
var items = ['réservé', 'premier', 'cliché', 'communiqué', 'café', 'adieu'];
items.sort(function (a, b) {
return a.localeCompare(b);
});
Пример: сортировка c помощью map
Функция сравнения (compareFunction) может вызываться несколько раз для каждого элемента в массиве. В зависимости от природы функции сравнения, это может привести к высоким расходам ресурсов. Чем более сложна функция сравнения и чем больше элементов требуется отсортировать, тем разумнее использовать map для сортировки. Идея состоит в том, чтобы обойти массив один раз, чтобы извлечь фактические значения, используемые для сортировки, во временный массив, отсортировать временный массив, а затем обойти временный массив для получения правильного порядка.
var list = ['Дельта', 'альфа', 'ЧАРЛИ', 'браво'];
var mapped = list. map(function(el, i) {
return { index: i, value: el.toLowerCase() };
});
mapped.sort(function(a, b) {
if (a.value > b.value) {
return 1; }
if (a.value < b.value) {
return -1; }
return 0;
});
var result = mapped.map(function(el) {
return list[el.index];
});
BCD tables only load in the browser
Оборудование для сортировки материалов в перерабатывающей, пищевой, горнодобывающей промышленности и в сфере обработки специализированных продуктов : TOMRA
Имея за плечами более 110 лет сортировки и промышленного производства, а также опыт установки оборудования в числе больше 10 500 единиц более чем в 80 странах мира, мы можем предоставить нашим заказчикам эффективные решения для сортировки и аналитики.
Использование синергии технологий, разработанных в рамках различных бизнес направлений, значительно расширяет возможность TOMRA Sorting находить новые приложения, сегменты и рынки для решений в области сортировки и аналитики. Теперь мы готовы быстрее, чем это было ранее отвечать на запросы, исходящие от потребителей и индустрии, предлагая продукцию высшего качества.
Теперь мы готовы быстрее, чем это было ранее отвечать на запросы, исходящие от потребителей и индустрии, предлагая продукцию высшего качества.
Имея опыт совместного с ведущими отраслевыми компаниями внедрения решений по сортировке в новые сегменты таких индустрий как пищевая промышленность, рециклинг, и горное дело, мы опираемся на него, чтобы предоставить нашим заказчикам отвечающие их потребностям инновационные решения.
Будучи частью семьи компаний TOMRA Sorting, мы можем расширять присутствие на глобальном рынке. Результатом более активной работы на локальном уровне являются предлагаемые нами лучшие условия продаж и сервиса, а также расширенная поддержка, обеспечивающая высокую эффективность и доступность наших решений.
Рост финансового потенциала компаний, объединенных TOMRA Sorting,внушает нашим партнерам уверенность в перспективах долгосрочного сотрудничества. Помимо увеличения инвестиций в исследования и разработки, которые помогают нам сохранять технологическое лидерство,мы также имеем возможность вкладывать средства по всему миру для более эффективного вхождения на новые рынки и новые сегменты рынка, а также располагаем необходимыми ресурсами для управления крупными и сложными проектами.
Помимо увеличения инвестиций в исследования и разработки, которые помогают нам сохранять технологическое лидерство,мы также имеем возможность вкладывать средства по всему миру для более эффективного вхождения на новые рынки и новые сегменты рынка, а также располагаем необходимыми ресурсами для управления крупными и сложными проектами.
Сортинг (секвенирование) фетальных клеток
Сортинг (секвенирование) фетальных клеток – это неинвазивный метод пренатальной диагностики и скрининга. Такое исследование проводится на 8-20 недели беременности, а объектом исследования являются нормобласты или лимфоциты плода, отделяющиеся от крови матери с помощью специального инструмента.
Такой метод диагностики полностью безопасен как для матери, так и для самого плода. А специалисты рекомендуют проводить такое исследование всем беременным женщинам, ведь оно позволяет выявить на ранних стадиях беременности серьезные проблемы у плода.
Зачем проводится сортинг фетальных клеток
Данное исследование позволяет на ранних сроках выявить у плода хромосомные и генные заболевания. Такие патологии приводят к тому, что ребенок рождается с различными уродствами или умственной отсталостью. Если во время скрининга обнаруживаются подобные нарушения, то женщине рекомендуется сделать аборт по медицинским показаниям. Ведь любые генные или хромосомные заболевания являются неизлечимыми и смертельно опасными, а ребенок, имеющий их, в большинстве случаев обречен на мучительную жизнь.
В каких случаях рекомендуется проводить такое исследование?
В последнее время все больше врачей настаивает на том, что любая женщина должна пройти пренатальную диагностику, в том числе пройти секвенирование фетальных клеток. Связано это с тем, что человек может и не догадываться, что является носителем «плохого» гена. А хромосомные заболевания и вовсе могут возникать по причине негативных внешних факторов.
Обязательным сортинг фетальных клеток является в следующих случаях:
- Ранние (до 18 лет) или поздние (после 35-40 лет) роды;
- Наличие в семье случаев рождения детей с генетическими заболеваниями;
- У матери и/или отца плода выявлен мутировавший ген;
- В роду были случаи хромосомных мутаций;
- Зачатие ребенка от близких родственников.

Секвенирование фетальных клеток в клинике Tel Aviv Medical Clinic
В израильском медицинском центре Tel Aviv Medical Clinic находится ведущее отделение пренатальной диагностики, в котором проводятся различные исследования. В том числе мы проводим секвенирование фетальных клеток. Данное исследование позволяет на ранних сроках обнаружить врожденные и неизлечимые заболевания.
Эта процедура полностью безопасная, ведь в нашей клинике работают высококвалифицированные специалисты, а используются дорогостоящие приборы, инструменты и оборудование.
xsl:sort | XSLT с примерами кода
При преобразовании документа элементами xsl:for-each и xsl:apply-templates, выбранные узлы по умолчанию обрабатываются в порядке просмотра документа, который зависит от выражения, использованного в атрибуте select этих элементов. XSLT позволяет изменять этот порядок посредством использования механизма сортировки.
Элементы xsl:for-each и xsl:apply-templates могут содержать один или несколько элементов xsl:sort, которые позволяют предварительно сортировать обрабатываемое множество узлов.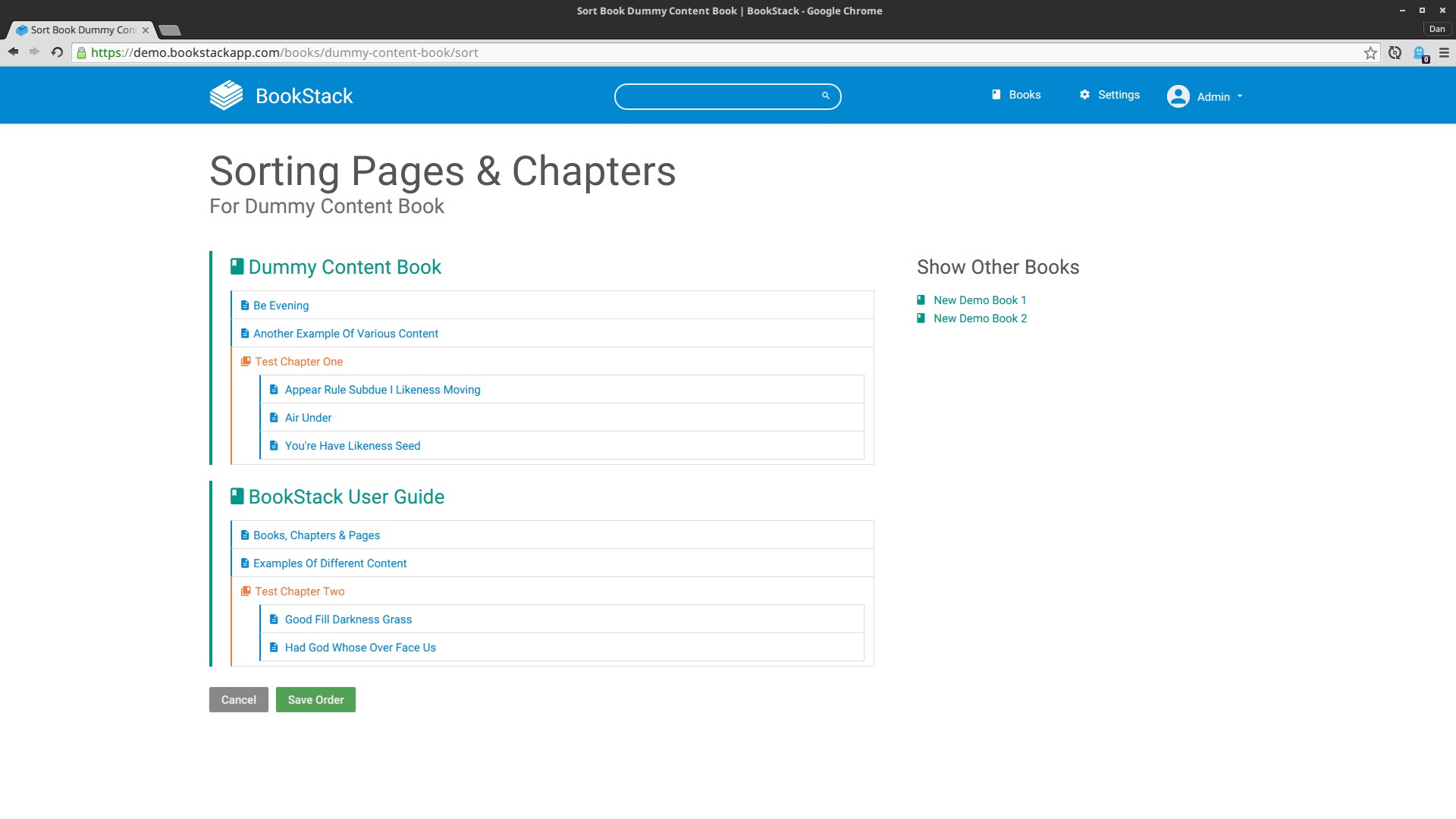
Синтаксис
<xsl:sort
select="string-expression"
lang="nmtoken"
data-type="text | number | qname-but-not-ncname"
order="ascending | descending"
case-order="upper-first | lower-first"
/>
Атрибуты:
select- обязательный атрибут, значением которого является выражение, называемое также ключевым выражением. Это выражение вычисляется для каждого узла обрабатываемого множества, преобразуется в строку и затем используется как значение ключа при сортировке. По умолчанию значением этого атрибута является «
.«, что означает, что в качестве значения ключа для каждого узла используется его строковое значение. order- необязательный атрибут, определяет порядок, в котором узлы должны сортироваться по своим ключам. Этот атрибут может принимать только два значения — «
ascending«, указывающее на восходящий порядок сортировки, и «descending«, указывающее на нисходящий порядок. Значением по умолчанию является «ascending«, то есть восходящий порядок. lang- необязательный атрибут, определяет язык ключей сортировки. Дело в том, что в разных языках символы алфавита могут иметь различный порядок, что, соответственно, должно учитываться при сортировке. Атрибут
langв XSLT может иметь те же самые значения, что и атрибутxml:lang(например: «en«, «en-us«, «ru» и т. д.). Если значение этого атрибута не определено, процессор может либо определять язык исходя из параметров системы, либо сортировать строки исходя из порядка кодов символовUnicode. data-type- необязательный атрибут, определяет тип данных, который несут строковые значения ключей. Техническая рекомендация XSLT разрешает этому атрибуту иметь следующие значения:
- «
text» — ключи должны быть отсортированы в лексикографическом порядке исходя из языка, определенного атрибутомlangили параметрами системы. Это значение используется по умолчанию;
- «
- «
number» — ключи должны сравниваться в численном виде. Если строковое значение ключа не является числом, оно будет преобразовано к не-числу (NaN), и, поскольку нечисловые значения неупорядочены, соответствующий узел может появиться в отсортированном множестве где угодно;
- «
- «
имя» — в целях расширяемости XSLT также позволяет указывать в качестве типа данных произвольное имя. В этом случае реализация сортировки полностью зависит от процессора.
- «
case-order- необязательный атрибут, указывает на порядок сортировки символов разных регистров. Значениями этого атрибута могут быть «
upper-first«, что означает, что заглавные символы должны идти первыми, или «lower-first«, что означает, что первыми должны быть строчные символы. К примеру, строки «ночь», «Улица», «фонарь», «Аптека», «НОЧЬ», «Фонарь» при использованииcase-order="upper-first"будут иметь порядок «Аптека», «НОЧЬ», «ночь», «Фонарь», «фонарь», «улица». При использовании case-order="lower-first"те же строки будут идти в порядке «Аптека», «ночь», «НОЧЬ», «фонарь», «Фонарь», «улица». Значениеcase-orderпо умолчанию зависит от процессора и языка сортировки. В большинстве случаев заглавные буквы идут первыми.
 Значением по умолчанию является «
Значением по умолчанию является « Это значение используется по умолчанию;
Это значение используется по умолчанию; При использовании
При использовании Описание и примеры
В случае если xsl:for-each и xsl:apply-templates содержат элементы xsl:sort, обработка множества узлов должна производиться не в порядке просмотра документа, а в порядке, который определяется ключами, вычисленными при помощи xsl:sort. Первый элемент xsl:sort, присутствующий в родительском элементе, определяет первичный ключ сортировки, второй элемент — вторичный ключ, и так далее.
Как можно видеть, элемент xsl:sort определяет сортировку достаточно гибко, но вместе с тем не следует забывать, что эти возможности могут быть реализованы в процессорах далеко не полностью. Поэтому одна и та же сортировка может быть выполнена в разных процессорах по-разному.
Приведем простой пример сортировки имен и фамилий.
Пример
Листинг 8.10. Входящий документ
<list>
<person>
<name>William</name>
<surname>Gibson</surname>
</person>
<person>
<name>William</name>
<surname>Blake</surname>
</person>
<person>
<name>John</name>
<surname>Fowles</surname>
</person>
</list>
Отсортируем этот список сначала по именам в убывающем, а затем по фамилиям в возрастающем порядке.
<xsl:template match="list">
<xsl:copy>
<xsl:for-each select="person">
<xsl:sort select="name" order="descending" />
<xsl:sort select="surname" />
<xsl:copy-of select="." />
</xsl:for-each>
</xsl:copy>
</xsl:template>
Листинг 8.12. Выходящий документ
<list>
<person>
<name>William</name>
<surname>Blake</surname>
</person>
<person>
<name>William</name>
<surname>Gibson</surname>
</person>
<person>
<name>John</name>
<surname>Fowles</surname>
</person>
</list>
К сожалению, сортировкой нельзя управлять динамически. Все атрибуты элемента
Все атрибуты элемента xsl:sort должны обладать фиксированными значениями.
Ссылки
Сортировка и фильтрация | Справочные статьи Smartsheet
При наличии соответствующих разрешений можно создавать фильтры для себя или для совместного использования с другими людьми. Нужен краткий обзор? См. статью Основы работы с фильтрами.
Например, вы можете создать доступный другим пользователям фильтр Текущий пользователь, чтобы все соавторы вашей таблицы могли быстро просматривать назначенные им задачи. Дополнительные сведения о создании доступного другим пользователям фильтра Текущий пользователь см. в статье Просмотр назначенных задач.
Описанные здесь возможности общих фильтров доступны в рамках планов «Бизнес» и «Корпоративный». Подробные сведения о планах с указанием их стоимости и функций, включённых в каждый план, см. на странице с расценками.
Необходимые разрешения для работы с фильтрами
Возможности работы с фильтрами напрямую зависят от наличия разрешений совместного доступа к соответствующей таблице.
| Действие с фильтром | Наблюдатель | Редактор | Владелец или администратор |
|---|---|---|---|
| Создание фильтра без имени | Да | Да | Да |
| Применение созданного фильтра | Да | Да | Да |
| Присвоение имени фильтру для последующего использования | Нет | Да | Да |
| Предоставление совместного доступа к фильтру всем соавторам (для плана «Для рабочих групп» или более высокого) | Нет | Нет | Да |
Дополнительные сведения о разрешениях совместного доступа на уровне таблицы см. в статье Уровни разрешений совместного доступа.
Создание и использование фильтров
Фильтрация данных с помощью фильтра без имени
При наличии доступа к таблице вы можете создать фильтр без имени для просмотра данных таблицы наиболее подходящим для вас способом. Конфигурация фильтра без имени будет уникальной для вас.
Конфигурация фильтра без имени будет уникальной для вас.
- На панели инструментов нажмите кнопку Фильтр > Создать фильтр.
Откроется форма создания фильтра. - В форме создания фильтра в разделе Показать совпадающие строки выберите условия, которые требуется применить к данным в таблице, и нажмите кнопку Применить, чтобы просмотреть результаты.
В меню Фильтр появится пункт Фильтр без имени, указывая на то, что ваши данные отфильтрованы в соответствии с указанными условиями.
СОВЕТ. Некоторые условия могут использоваться только с определёнными типами данных. Например, условие «содержит» можно использовать только с текстовыми строками и контактами, а «находится между» — только с датами и числами.
Присвоение фильтру имени для его сохранения или предоставления совместного доступа
Если у вас есть права редактора (или выше) на доступ к таблице, вы можете присвоить фильтру имя, чтобы сохранить его для использования в будущем. При наличии прав администратора вы можете предоставить доступ к фильтру с именем всем участникам рабочей группы, которые имеют разрешение на доступ к таблице.
При наличии прав администратора вы можете предоставить доступ к фильтру с именем всем участникам рабочей группы, которые имеют разрешение на доступ к таблице.
Только пользователи учётных записей планов «Бизнес», «Корпоративный» и «Премьер» могут предоставлять совместный доступ к фильтру другим соавторам.
- В поле Имя укажите имя фильтра.
- Установите флажок Совместный доступ к фильтру, чтобы сделать фильтр доступным любому, имеющему доступ к таблице.
Определить, к каким из фильтров администратор таблицы предоставил совместный доступ, можно с помощью индикатора совместного доступа рядом с именем фильтра.
Изменение фильтра
После создания фильтра вы в любой момент можете внести изменения в его критерии (условия, в зависимости от которых данные отображаются или скрываются). Для изменения фильтра выполните указанные ниже действия.
- Примените к таблице фильтр, который требуется изменить (для этого выберите его в меню Фильтр).
ПРИМЕЧАНИЕ. Если у вас нет прав редактора или прав более высокого уровня, вы можете изменять только фильтр без имени.
- В меню Фильтр наведите курсор мыши на имя фильтра и щёлкните значок редактирования .
СОВЕТ. В заголовке формы будет показано имя изменяемого фильтра. Проверьте заголовок и убедитесь в том, что вы редактируете именно тот фильтр, который нужно.
- В форме «Изменить фильтр» задайте новые условия и нажмите кнопку Применить.
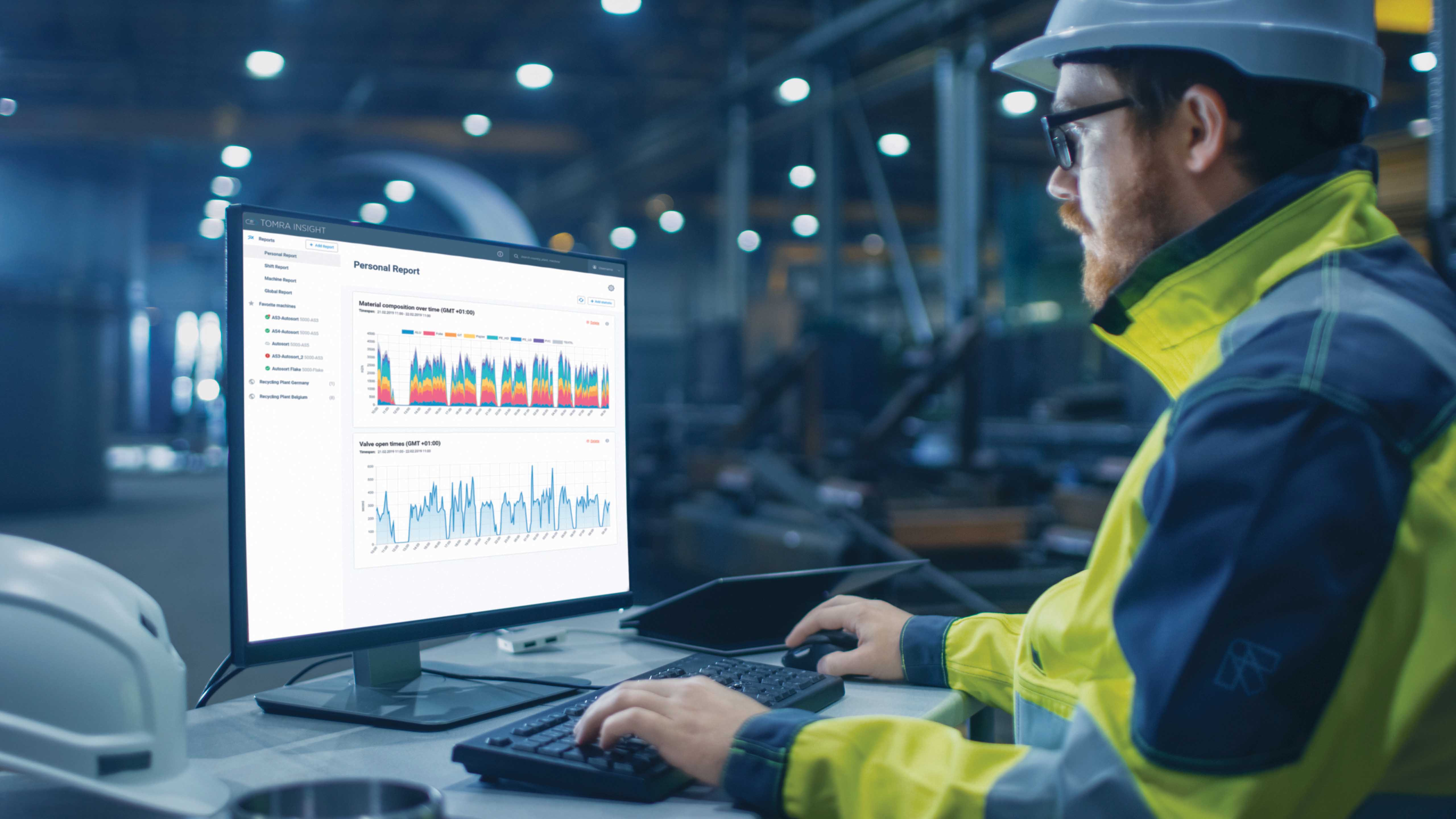
Обновленный фильтр будет применен к таблице.
Снятие фильтра
Чтобы сбросить фильтр (больше не применять его к таблице), нажмите кнопку Выключить фильтр.
Удаление фильтра
Чтобы удалить фильтр (из таблицы и из меню), выберите его в меню Фильтр, чтобы применить к таблице, а затем нажмите Удалить текущий фильтр.
Советы по работе с условиями
Указывая условия фильтров, вы быстро научитесь добиваться желаемого результата. Вот несколько советов начинающим.
Вот несколько советов начинающим.
- Изменение интерпретации условия. Чтобы указать, должны ли выполняться все указанные условия или хотя бы одно из них, щёлкните ссылку рядом с пунктом Показать совпадающие строки для переключения между режимами все условия и хотя бы одно условие.
- Фильтр для пустых ячеек. Чтобы найти строки с отсутствующими данными, используйте условие пусто.
- Включать родительские строки. Если в таблице имеется иерархия элементов, вы можете выбрать, следует ли включать родительские строки в фильтр, с помощью флажка Включать родительские строки. Дополнительные сведения об иерархии в таблице см. в справочной статье Иерархия: отступы и выступы строк.
- Фильтр для назначенных вам задач. Чтобы соавторы могли видеть только назначенные им задачи, создайте фильтр Текущий пользователь. Дополнительные сведения об этом см. в статье Просмотр назначенных задач.
- С помощью условия фильтра Строка можно сузить результаты по критическому пути, вложениям, комментариям и заблокированным строкам. Дополнительные сведения см. в разделе ниже.
 Дополнительные сведения об этом см. в статье Просмотр назначенных задач.
Дополнительные сведения об этом см. в статье Просмотр назначенных задач.Фильтрация по критическому пути, вложениям, комментариям и заблокированным строкам
Критический путь, вложения, комментарии и заблокированные строки можно использовать в качестве условия фильтра для отображения или скрытия определённых строк. С помощью условия фильтра Строка можно ограничить отображаемое содержимое задачами критического пути, вложениями и комментариями, требующими выполнения определённых действий, а также строками, редактирование которых заблокировано для конкретных пользователей.
В первом раскрывающемся списке выберите пункт Строка, чтобы увидеть доступные варианты.
Выделение критического пути с помощью фильтра
Если в таблице настроено выделение строк, относящихся к критическому пути, можно применить фильтр с условием находится в критическом пути или не находится в критическом пути, чтобы отобразить или скрыть такие строки. Инструкции по включению критического пути в таблице см. в статье Отслеживание критического пути проекта.
Инструкции по включению критического пути в таблице см. в статье Отслеживание критического пути проекта.
Фильтрация для быстрого поиска строк с вложениями и комментариями
Вы можете создать фильтр с условием «Строка» для отображения или скрытия строк, содержащих вложения или комментарии. Используйте условие имеет вложения или имеет комментарии, чтобы быстро загрузить вложения или ответить на комментарии. С помощью условия не имеет вложений или не имеет комментариев можно скрыть строки с вложениями или комментариями.
Дополнительные сведения о работе с вложениями и комментариями в таблицах см. в следующих справочных статьях:
Поиск заблокированных и незаблокированных строк с помощью фильтра
Используйте условие фильтра Строка находится в заблокированном состоянии или Строка не находится в заблокированном состоянии для отображения или скрытия строк, изменять которые могут только пользователи, имеющие разрешения совместного доступа к таблице уровня администратора. Таким образом пользователи с разрешениями редактора могут отфильтровывать строки, которые им разрешено изменять.
Таким образом пользователи с разрешениями редактора могут отфильтровывать строки, которые им разрешено изменять.
Дополнительные сведения о заблокированных строках см. в статье Установка и снятие блокировки столбцов и строк.
Using NX Assemblies and Mechatronics Concept Designer to help design a sorting machine.
Это обязательное поле
Укажите действующий электронный адрес
Это обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Это обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Это обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Страна *АвстралияАвстрияАзербайджанАландские островаАлбанияАлжирАмериканское СамоаАнгильяАнголаАндорраАнтарктидаАнтигуа и БарбудаАргентинаАрменияАрубаАфганистанБагамыБангладешБарбадосБахрейнБеларусьБелизБельгияБенинБермудские островаБолгарияБоливияБонэйрБосния и ГерцеговинаБотсванаБразилияБританская Территория в Индийском ОкеанеБританские Виргинские островаБрунейБуркина-ФасоБурундиБутанВануатуВатиканВеликобританияВенгрияВенесуэлаВиргинские острова (США)Внешние малые острова СШАВосточный ТиморВьетнамГабонГаитиГайанаГамбияГанаГваделупаГватемалаГвинеяГвинея-БисауГерманияГернсиГибралтарГондурасГонконгГренадаГренландияГрецияГрузияГуамДанияДемократическая республика КонгоДжибутиДоминикаДоминиканская РеспубликаЕгипетЗамбияЗападная СахараЗимбабвеИзраильИндияИндонезияИорданияИракИранИрландияИсландияИспанияИталияЙеменКабо-ВердеКазахстанКаймановы островаКамбоджаКамерунКанадаКатарКенияКипрКирибатиКитайКокосовые острова (Килинг)КолумбияКоморыКонгоКоста-РикаКот-д’ИвуарКубаКувейтКыргызстанКюрасаоЛаосЛатвияЛесотоЛиберияЛиванЛивияЛитваЛихтенштейнЛюксембургМаврикийМавританияМадагаскарМайоттаМакаоМакедонияМалавиМалайзияМалиМальдивыМальтаМароккоМартиникаМаршалловы островаМехикоМозамбикМолдавияМонакоМонголияМонсерратМьянмаНамибияНауруНепалНигерНигерияНидерландыНикарагуаНиуэНовая ЗеландияНовая КаледонияНорвегияОбъединенные Арабские ЭмиратыОманОстров БувеОстров ДжерсиОстров МэнОстров НорфолкОстров РождестваОстров Святой ЕленыОстров ФиджиОстров Херд и острова МакдональдОстрова КукаОстрова ПиткэрнПакистанПалауПалестинаПанамаПапуа-Новая ГвинеяПарагвайПеруПольшаПортугалияПуэрто-РикоРеюньонРоссийская ФедерацияРуандаРумынияСШАСальвадорСамоаСан-МариноСан-Томе и ПринсипиСаудовская АравияСвазилендСеверная КореяСеверные Марианские островаСейшельские островаСен-БартелемиСен-МартенСен-Пьер и МикелонСенегалСент-Винсент и ГренадиныСент-Китс и НевисСент-ЛюсияСербияСингапурСинт-МартенСирияСловакияСловенияСоломоновы островаСомалиСуданСуринамСьерра-ЛеонеТаджикистанТаиландТайваньТанзанияТеркс и КайкосТогоТокелауТонгаТринидад и ТобагоТувалуТунисТуркменистанТурцияУгандаУзбекистанУкраинаУоллис и ФутунаУругвайФарерские островаФедеративные штаты МикронезииФилиппиныФинляндияФолклендские острова (Мальвинские острова)ФранцияФранцузская ГвианаФранцузская ПолинезияФранцузские Южные территорииХорватияЦентральноафриканская РеспубликаЧадЧерногорияЧешская РеспубликаЧилиШвейцарияШвецияШпицберген и Ян-МайенШри-ЛанкаЭквадорЭкваториальная ГвинеяЭритреяЭстонияЭфиопияЮжная АфрикаЮжная Георгия и Южные Сандвичевы ОстроваЮжная КореяЮжный СуданЯмайкаЯпонияЭто обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Это обязательное поле
Укажите действующий номер телефона
Должностные функции *OtherЗакупкиИТМаркетингМенеджер по проектамОтдел кадровОтдел продажПроизводствоРазработкаСтудент/преподавательТехническая поддержкаЮридический/финансовый отделЭто обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Должность *Высший менеджментМенеджерПользователь/администраторСтарший менеджерЭто обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Предпочитаемый язык *ChineseCzechEnglishFrenchGermanItalianJapaneseKoreanPolishPortugueseRussianSpanishЭто обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Отрасль *Автомобилестроение и транспортАкадемическая программаАэрокосмическая и оборонная промышленностьМедицина и фармацевтикаПотребительские товары и розничная торговляСудостроениеТяжелое машиностроение и промышленное оборудованиеЭлектроника и полупроводниковые устройстваЭнергетика и городская инфраструктураЭто обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Это обязательное поле
Недопустимое значение, либо превышено допустимое число символов
Это обязательное поле
Недопустимое значение, либо превышено допустимое число символов
* Обязательное поле
Отправить
Разбирая | Управление ТБО
Целью каждого предприятия по утилизации материалов является отделение, восстановление и подготовка перерабатываемых продуктов высочайшего качества наиболее эффективно и безопасно с наименьшими затратами. Технологии сортировки, включая оптические сортировщики и робототехнику, постоянно развиваются, чтобы обеспечить более высокую производительность, но большинство специалистов отрасли подчеркивают, что для достижения оптимальных результатов необходимо образование.
Технологии сортировки, включая оптические сортировщики и робототехнику, постоянно развиваются, чтобы обеспечить более высокую производительность, но большинство специалистов отрасли подчеркивают, что для достижения оптимальных результатов необходимо образование.
«Благодаря двойному потоку вы получаете более качественный посевной материал, чем однопоточный», — говорит Боб Гарднер, старший вице-президент SCS Engineers Technology.Сортировка на обочине снижает загрязнение. Однако, добавляет он, это требует государственного просвещения и охраны правопорядка. Он говорит, что уровень заражения в Кливленде составляет 90%; большинство вторсырья, которое некоторые жители тратят время на разделение, все равно попадает на свалку из-за загрязнения.
Загрязнение широко распространено. По словам Феликса Хоттенштейна, директора по продажам MSS Optical Sorters, подразделения оптической сортировки, в связи с китайской программой «Национальный меч», налагающей более жесткие ограничения на зараженные отходы и запрещающей вывоз определенных видов отходов из Америки, некоторые китайские компании начали приезжать сюда, чтобы получить более чистый продукт. компании CP Group.«Некачественный материал теперь отправляется на свалку».
компании CP Group.«Некачественный материал теперь отправляется на свалку».
Выполнение сортировки здесь позволяет китайским компаниям экспортировать только чистый, пригодный для утилизации материал. Кроме того, по словам Гарднера, «Китай приобрел бумажные фабрики в США, чтобы производить собственную целлюлозу». Владение предприятиями в Америке экономит место в их родной стране и повышает уровень контроля над процессом. Кроме того, отмечает Гарднер, «им не нужно утилизировать остатки в Китае».
Hottenstein рассматривает эту политику как стимул для улучшения качества материала и эффективности сортировочного оборудования.«Это заставляет всех нас стать лучше».
Грег Гезелл, инженер-механик из HDR, согласен — до некоторой степени. Он считает, что в основе проблемы лежит экономика утилизации, и что национальный меч — лишь часть этого. «Произошло бы резкое снижение цен без National Sword? Может быть.»
Он предлагает пересмотреть наши методы переработки, чтобы улучшить качество или вернуться к высокому качеству, вместо того, чтобы сосредотачиваться главным образом на количестве или отводе на свалку. «Многие неэффективные и небольшие системы столкнулись с трудностями, — говорит Гезелл, — тем не менее, все еще есть сообщества, инвестирующие в модернизацию систем или даже в целые технологические линии, которые сейчас вкладывают средства в подготовку к лучшим временам.
«Многие неэффективные и небольшие системы столкнулись с трудностями, — говорит Гезелл, — тем не менее, все еще есть сообщества, инвестирующие в модернизацию систем или даже в целые технологические линии, которые сейчас вкладывают средства в подготовку к лучшим временам.
Один из примеров, который Гезелл приводит в качестве положительного результата проекта National Sword, — это предприятие, которое было готово к вводу в эксплуатацию с совершенно новой основной системой сортировки, которая, как ожидалось, увеличит утечку и произведет большое количество картона и смешанной бумаги, а также как контейнеры всех типов. Прежде чем они смогли начать работу, предприятие должно было признать, что качество волокна из их системы не будет востребованным на рынке. Им нужно было изменить свой процесс и цели. «Дорого, но необходимо», — говорит он, добавляя, что теперь предприятие может производить товарные товары.
Ужесточение китайских стандартов импорта вторсырья сыграло свою роль в создании того, что Тони Бондс, менеджер по маркетингу CP Group, называет «перенасыщением внутреннего лома в США». Поскольку внутренний спрос остается низким, а стоимость смешанной бумаги, пластика и металлов снижается, это создает нагрузку на операции MRF. Вот почему, добавляет он, «основное внимание CP Group уделяется проектированию оборудования, MRF и процессов обработки материалов, которые максимизируют восстановление для наших клиентов».
Поскольку внутренний спрос остается низким, а стоимость смешанной бумаги, пластика и металлов снижается, это создает нагрузку на операции MRF. Вот почему, добавляет он, «основное внимание CP Group уделяется проектированию оборудования, MRF и процессов обработки материалов, которые максимизируют восстановление для наших клиентов».
Грохот Van Dyk без упаковки
Принимая вызов
Несколько лет назад Гезелл заявил, что было невозможно добиться успеха в Institute of Scrap Recycling Industries Inc.стандарты на запрещенные материалы и выбросы — загрязнители — для изделий из волокна. Также было «очень сложно» получить заданные уровни загрязнения для категорий пластмасс в условиях эксплуатации и с имеющимся оборудованием для однопоточных MRF — отчасти потому, что «основное внимание уделялось количеству переработки и меньше — качеству».
«Уровни загрязнения в пять, восемь или даже десять процентов для некоторых материалов были недостижимы», — говорит Гезелл. «Часто при демонстрации производительности на новом MRF соглашались достичь« приемки завода ».«Это означает, что если комбинат принял товар, то приемка MRF была достигнута. Этот подход работал до тех пор, пока завод не повышал свои требования — но тогда это сделал Китай.
«Часто при демонстрации производительности на новом MRF соглашались достичь« приемки завода ».«Это означает, что если комбинат принял товар, то приемка MRF была достигнута. Этот подход работал до тех пор, пока завод не повышал свои требования — но тогда это сделал Китай.
Современные технологии способны достичь большего. Когда стандарт был впервые введен, Гезелл говорит, что немногие поставщики оборудования были готовы перейти на уровень загрязнения 0,5% от National Sword. Сегодня все по-другому, хотя он говорит, что важно тщательно прояснить и определить, как будут демонстрироваться требуемые стандарты.
Эллиптический сепаратор Van Dyk отбрасывает трехмерный материал.
Способность предприятия достигать уровней производительности, приближающихся к требованиям National Sword, часто является результатом многих факторов, в том числе более положительной сортировки, когда желаемый материал сортируется из смешанного потока, с упором на предотвращение загрязнения MRF , более низкие требования к пропускной способности и другие причины, а также более высокая производительность оборудования, перечисляет Gesell. Кроме того, местное образование и принятие жителями стандартов качества очень важны для позиционирования учреждения, чтобы оно могло соответствовать высоким стандартам качества.
Кроме того, местное образование и принятие жителями стандартов качества очень важны для позиционирования учреждения, чтобы оно могло соответствовать высоким стандартам качества.
«Начало работы с сырьем более высокого качества помогает», — отмечает Гезелл, добавляя, что современные требования к качеству требуют более высоких технологий для более крупных MRF. Он считает, что тщательный подбор и компоновка оборудования позволит обеспечить высочайшие гарантии качества продукции. «При работе оборудования следует также учитывать способность поддерживать эти уровни производительности для текущих операций».
Трехступенчатая система Walair компании Van Dyk
Процесс сортировки
По словам Гарднера, для улучшения качества материалов произошли «значительные изменения в оптической и роботизированной сортировке».По его словам, оптическая сортировка пластмасс основана на спектральных характеристиках, и робототехника развивается, чтобы минимизировать проблемы, связанные с трудом, здоровьем и безопасностью, особенно с такими предметами, как острые предметы.
Среди достижений, над которыми работает SCS, — это приложение в Миннесоте, где роботы разделяют пакеты для домашней органики, программу переработки и компост. Оптический сортировщик запрограммирован на спектральные характеристики. «Проблема в весе, — говорит Гарднер, — и в скорости. Сколько вам нужно роботов? »
Датчики указывают, где находятся предметы; роботы должны их схватить.Проблема, поясняет Гарднер, заключается в интеграции программного обеспечения для согласования механики с оптикой. «Эффективность оптических сортировщиков зависит от того, насколько глубоко, широко и быстро материал находится на ленте».
Качество оптических и роботизированных сортировщиков зависит от того, как подготовлен материал, утверждает Марк Нейтци, который говорит, что Van Dyk Recycling Solutions «работает над подготовкой за кулисами для загрузки сортировщика».
DeftAir компании Van Dyk помогает в подготовке материала. Van Dyk
Один слой гомогенизированного материала легче всего отсортировать. «Материал должен быть однослойным», — подчеркивает Нейтци. SCS производит оборудование, которое помогает сделать оптические сортировщики и роботов более успешными благодаря скорости, точности и частоте попаданий, включая как извлечение, так и чистоту. Однослойность — это одна из основных задач, но Нейтци говорит, что «большая часть оборудования покупается из-за пакетов с пленкой».
«Материал должен быть однослойным», — подчеркивает Нейтци. SCS производит оборудование, которое помогает сделать оптические сортировщики и роботов более успешными благодаря скорости, точности и частоте попаданий, включая как извлечение, так и чистоту. Однослойность — это одна из основных задач, но Нейтци говорит, что «большая часть оборудования покупается из-за пакетов с пленкой».
Все начинается с калибровочного грохота: 440 мил — это диаметр вращающегося вала, необходимый для удаления пакетов с пленкой и подготовки материалов, — говорит Нейтзи. «Это огромный кусок головоломки.Далее идет эллиптический сепаратор, или баллистический сепаратор, с лопастями, которые отбрасывают трехмерный материал назад и поднимают двумерные материалы вверх — такие материалы, как пленка, газета и белая бумага. Он называет это «разумным разделением» и говорит, что оптические сортировщики «ненавидят плавающий материал».
После грохота и баллистического сепаратора идет оптический сортировщик, за которым следует «проверка качества робота», — перечисляет Нейтци. «Роботы хороши в правильном приложении, если поток подготовлен». Чтобы помочь с этой подготовкой, DeftAir — в основном кожух на конвейерной ленте с вентиляторами, которые работают с той же скоростью, что и ленты, для стабилизации материала и достижения большей производительности — позволяет оптическому сортировщику работать с максимальной скоростью.
«Роботы хороши в правильном приложении, если поток подготовлен». Чтобы помочь с этой подготовкой, DeftAir — в основном кожух на конвейерной ленте с вентиляторами, которые работают с той же скоростью, что и ленты, для стабилизации материала и достижения большей производительности — позволяет оптическому сортировщику работать с максимальной скоростью.
Еще одним инструментом подготовки является WalAir, устройство разделения плотности, которое создает поток воздуха, который проходит через барабан и направляется в разделительную коробку для легких, средних и тяжелых материалов. «Компании« уменьшают вес »пластиковых бутылок», — отмечает Нейтци. В результате получается 5% ПЭТ в потоке отходов — около 42 бутылок на фунт, или 1600 бутылок в минуту.
«Роботы занимают место и могут двигаться только так быстро», — продолжает Нейтци. Чтобы они достигли процента точности в середине 90-х по скорости попадания и чистоте, использование оптического сортировщика шириной 9 футов со скоростью ленты 800 футов в минуту может позволить роботам собирать до 2000 бутылок в минуту. Однако он говорит, что 90% MRF используют только механическое разделение.
Однако он говорит, что 90% MRF используют только механическое разделение.
CP Group ответом на сортировку — это CP Auger Screen, единственное в своем роде устройство, в котором используется серия подвижных консольных шнеков, которые не оборачиваются, объясняет Бондс. Разработанный для фракционирования материала по размеру, он достаточно универсален, чтобы его можно было использовать в качестве основного грохота, скальпера или грохота для мелких частиц.
Сетка CP Anti-Wrap, также разработанная для уменьшения обертывания, отделяет газетную бумагу от крупных волокон. Большая окружность вала предотвращает заворачивание проблемных материалов, что сокращает объем необходимой очистки и обслуживания.Бондс добавляет, что замена одинарных дисков с болтовым креплением также выполняется быстро и просто.
Беспокойство, связанное с разлукой
На это потребовались годы, но Гезелл говорит, что робототехника наконец-то стала популярной благодаря более совершенным датчикам, более успешным методам сбора и повышению безопасности. Теперь рядом с ручными сортировщиками можно разместить удобных роботов. Есть даже роботы для C&D и электронных отходов — и они становятся все более доступными.
Теперь рядом с ручными сортировщиками можно разместить удобных роботов. Есть даже роботы для C&D и электронных отходов — и они становятся все более доступными.
Однако из-за ограничений скорости и конструкции, которая позволяет им захватывать только один предмет за раз, роботы не могут конкурировать с оптическими сортировщиками в массовых применениях, считает Гезелл.«Робот может выполнять роль контроля качества, дополняя оптический сортировщик, захватывая материалы меньшего объема или восстанавливая пропущенные предметы на линии остатков. В этих типах ролей количество выборок в час может быть не столь важным, но робот не устает и его можно обучить искать более одного типа материала. Эта технология отлично справляется с распознаванием многих типов товаров [и] может быть сконструирована для работы с материалами любого размера и веса ». Таким образом, по его словам, они используются в инновационных приложениях для всех типов операций по переработке, а не только в однопоточных приложениях.
Тем не менее, это необходимо для повышения скорости успешной комплектации. Тем не менее, Gesell ожидает, что постоянные улучшения и снижение затрат сделают его конкурентоспособным по сравнению с другими сортировщиками и технологиями, за которыми нужно следить.
Еще один развивающийся сортировщик — это оптический сортировщик, который начал свою деятельность с улавливания контейнеров большого объема, в частности, бутылок из-под воды из ПЭТ. «Они по-прежнему являются лидером по объемам, но теперь используются в типичных MRF во многих местах с большими объемами для всех типов контейнеров и бумаги во многих инновационных приложениях, сокращающих трудозатраты», — отмечает Гезелл.
Новым в оптических сортировщиках является усовершенствование датчиков, усовершенствованная конструкция корпуса и устройства, повышающие точность и способность поддерживать эту точность, лучшее распределение воздуха, большее количество форсунок, потребности в техническом обслуживании и безопасность. Некоторые ранние модели модернизируются для улучшения их характеристик.
Некоторые ранние модели модернизируются для улучшения их характеристик.
На сортировочной линии количество успешных подборок в минуту может исчисляться тысячами — почти то, что может быть должным образом доставлено ускоряющим конвейером, заменяя тем самым несколько сортировщиков.Поставщики оборудования очень изобретательны, они используют бригады оптических сортировщиков для захвата нескольких товаров и разделения их на определенные товары.
Оптические сортировщики могут превосходить ручные сортировщики волокон и контейнеров во многих областях, говорит Гезелл, не только потому, что они могут быть быстрее, но также потому, что, если они оснащены правильными датчиками, они могут принимать решения по вопросам качества материала.
Датчики
Датчики имеют решающее значение для успеха роботизированных и оптических сортировщиков, твердо убежден Гезелл.«Повышение разрешения и скорости зондирования привело к созданию более совершенной технологии ближнего инфракрасного диапазона, чем было возможно во многих ранних предложениях».
Теперь NIR используется с обнаружением цвета в более широком спектре, и при необходимости некоторые поставщики могут предложить другие технологии, заимствованные из пищевой, горнодобывающей или других отраслей. Некоторые из наиболее распространенных технологий включают электромагнитные и индукционные, рентгеновские (передача и флуоресценция), инфракрасные лучи (рассеивание тепла или поглощение света), специализированные лазеры, плотность, твердость и другие методы, позволяющие более четко отличать желаемые материалы от загрязняющих веществ.«Большинство MRF не нуждаются в этих передовых технологиях, но система, разработанная с учетом будущих изменений, очень важна», — заключает Гезелл.
Он приводит примеры, такие как лучшая сортировка по цвету и определение того, является ли лист бумаги слишком влажным, грязным или слишком много чернил для конкретного продукта. «Или они могут сортировать типы металла, компоста или электронных отходов». ПЭТ можно сортировать по бутылкам и по цвету. Технологии могут определить, заполнена ли бутылка наполовину; распознавать ПЭТ-этикетки на других типах тары; определить черный ПЭТ; различать модифицированную гликолем пленку из ПЭТ-G, гибкие контейнеры, грейферы, листы или другие типы контейнеров; и определить, не слишком ли загрязнен объект ПЭТ.
Технологии могут определить, заполнена ли бутылка наполовину; распознавать ПЭТ-этикетки на других типах тары; определить черный ПЭТ; различать модифицированную гликолем пленку из ПЭТ-G, гибкие контейнеры, грейферы, листы или другие типы контейнеров; и определить, не слишком ли загрязнен объект ПЭТ.
Эти методы могут увеличить скорость улавливания, уменьшить количество загрязняющих веществ, расширить ассортимент продуктов и дополнительно разделить продукты, тем самым увеличивая ценность производимых товаров. Хотя многие из этих методов могут быть полностью использованы только при очень крупной или специализированной сортировке, наличие оборудования, способного использовать эти методы, является полезным. Например, Гезелл объясняет, что, хотя смешанные пластмассы (№№ 3–7) не могут быть легко проданы в сегодняшних условиях, полипропилен (ПП №5) из смешанных пластмасс можно продавать в целом, а отделение поливинилхлорида (ПВХ № 3) и материалов, содержащих антипирены, улучшает топливные свойства оставшихся смешанных пластмасс и остатков MRF, потенциально снижая потребность в захоронении.
Как и сотовые телефоны, камеры и телевизоры, датчики постоянно развиваются для достижения лучшего разрешения, говорит Хоттенштейн. Указывая на то, что MSS Optical Sorters построили первый сортировщик датчиков в 1989 году, он объясняет, как они используют инфракрасное излучение для идентификации пластмасс, потому что разные длины волн отражаются по-разному.«Сегодня они более сложные и сканируют быстрее, с лучшим разрешением, отслеживая более мелкие частицы и больший объем».
Новые машины делают то, чего не могли делать старые, продолжает Хоттенштейн, ссылаясь на ПЭТ-бутылки с термоусадочными этикетками как на пример значительного улучшения. «Он распознает бутылку за этикеткой и отправляет на переработку. Это более высокий уровень сложности «.
Более высокое разрешение также позволяет сортировщикам видеть меньшие контейнеры и раздавленные предметы, а также пакеты с многослойными материалами, в зависимости от конструкции упаковки.«Машины выполняют задачи, недоступные людям, — например, сортировку полиэтилена и полипропилена», — говорит Хоттенштейн. «Они более эффективны, чем ручные сортировщики, не беспокоясь о повторяемости или безопасности».
«Они более эффективны, чем ручные сортировщики, не беспокоясь о повторяемости или безопасности».
В эпоху, когда трудно найти ручные сортировщики, это может быть большим преимуществом для MRF. «Машина выполняет большую часть работы», — говорит Готтенштейн. «Люди [служат] контролем качества».
Purity
Датчики с более высоким разрешением имеют повышенный уровень чистоты: 95–98%, утверждает Хоттенштейн.Но технология стоит денег, и ему приходится задавать вопрос: «Гарантирует ли более высокий процент чистоты новую машину?»
Модернизация MRF для получения более качественных сортов стала основным источником дохода для оптических сортировщиков MSS. MRF в Индианаполисе, штат Индиана, которому было 10–15 лет и не имело сортировочного оборудования, был модернизирован с использованием передовых технологий. Однако, по словам Готтенштейна, не каждое сообщество считает, что затраты оправданы. «Если города решат, что это проблема — если она стоит слишком дорого или доставляет слишком много хлопот, — они не сделают этого. «Это ценностное решение, но часто все сводится к деньгам.
«Это ценностное решение, но часто все сводится к деньгам.
Для операторов MRF, заинтересованных в повышении чистоты своего волокнистого материала, Bonds предлагает CIRRUS FiberMax. По данным CP Group, он разработан для обеспечения более высокого уровня чистоты газет и смешанной бумаги, он работает до 40 раз быстрее, чем ручные сортировщики, с более чем 1000 отборов в минуту. Он может точно извлекать смешанную бумагу или сортировать запрещенные предметы, такие как пластиковые бутылки, металлы, пленка и мусор.
MSS PlasticMax также может сортировать практически любой тип материала, как положительно, так и отрицательно.L-VIS и MetalMiner восстанавливают металл для ASR, электронного лома и других промышленных применений.
Выталкивающий кожух PrecisionFlow для оптических сортировщиков от MSS контролирует траекторию движения легких материалов, таких как гибкая пластиковая упаковка или отдельные листы бумаги. «Благодаря оптимизированной форме кожуха мы можем лучше контролировать траектории внутри вытяжного кожуха PrecisionFlow. Это обеспечивает нашим клиентам более высокую эффективность разделения, увеличивая удаление гибкой пластиковой упаковки из загрязненных бумажных потоков.Это также улучшает положительную сортировку волокна, такого как сортированная офисная бумага », — говорит Хоттенштейн. Независимые сторонние испытания показывают, что выталкивающий кожух сыграл важную роль в 97% -ном восстановлении гибкой пластиковой упаковки от загрязненных бумажных потоков.
Это обеспечивает нашим клиентам более высокую эффективность разделения, увеличивая удаление гибкой пластиковой упаковки из загрязненных бумажных потоков.Это также улучшает положительную сортировку волокна, такого как сортированная офисная бумага », — говорит Хоттенштейн. Независимые сторонние испытания показывают, что выталкивающий кожух сыграл важную роль в 97% -ном восстановлении гибкой пластиковой упаковки от загрязненных бумажных потоков.
В целом, оптические сортировщики MSS имеют коэффициент извлечения 94% или выше, но для максимального извлечения материала MSS использует высокоскоростную ленту со скоростью 1000 футов в минуту, чтобы обеспечить улучшенное распределение материала и меньшее покрытие ленты для минимальной потери хорошего волокна. .
Оптический сортировщик Machinex, Mach HyspecMachinex
Технологии: усовершенствования и инновации
Поплавок для пленки и легкой листовой бумаги. «Пакеты для пленки не отделяются от бумаги; по этой причине мы не продаем бумагу в Китай », — говорит Нейтци. По его словам, именно поэтому вместо бумаги говорят об оптических сортировках. «Вы можете производить положительную сортировку бумаги, используя оптический сортировщик, чтобы избавиться от загрязнений». Он упоминает более новый Plano, TX, MRF, в котором есть три строки положительной сортировки.
По его словам, именно поэтому вместо бумаги говорят об оптических сортировках. «Вы можете производить положительную сортировку бумаги, используя оптический сортировщик, чтобы избавиться от загрязнений». Он упоминает более новый Plano, TX, MRF, в котором есть три строки положительной сортировки.
Или процесс можно перевернуть, и бумагу можно выбросить из-под загрязнения. Этот метод оказался успешным на двух установках. Хотя он говорит, что положительный сорт более эффективен и дает более чистую бумагу, он говорит, что здесь больше места для ошибок и используется больше воздуха. Тем не менее, при правильном разделении и подготовке положительная сортировка может сделать бумагу без пленочных пакетов.
К сожалению, по его словам, большинство MRF, построенных с 2002 по 2013 год, не имеют необходимой технологии для работы с мешками.При средней системе, способной обрабатывать 35 тонн в час и в среднем 212 000 мешков в час, поступающих в систему, по оценкам Нейтци, только для пленки потребуется 60 сортировщиков.
Робот-сортировщик Machinex, SamurAIMachinex
Цели на будущее
Новое предприятие MRF в штате Мэн оснащено оптическими сортировщиками для восстановления пластмасс №1 и №2, черных металлов, таких как олово и алюминий, и картона для традиционных рынков вторичной переработки. Пластиковая пленка перебирается.
«Все остальное идет на варку целлюлозы», — указывает Гарднер.Там он проходит дополнительную сепарацию и продается на топливо. То, что осталось, отправляется на свалку. «Есть несколько способов — переработка или переработка целлюлозы. Нет смысла в переработке смешанной бумаги; есть только ценность в целлюлозе ». Компания Coastal Resources, MRF, производит товарную чистую целлюлозную массу, которую регенерируют из смешанной бумаги и продают на товарном рынке.
Переработка пластмасс №1 и №2, металла и картона имеет дополнительную ценность, если их уровень чистоты достаточно высок.«Загрязнение — это большое дело», — заявляет Гарднер, хотя и говорит, что в штате Мэн это не такая серьезная проблема из-за большого объема смешанной бумаги.
MRF штата Мэн обслуживает 85 населенных пунктов, перерабатывая примерно 180 000 тонн в год с отклонением 70–80% (требуется 50%). Coastal Resources использует инновационную технологию вторичной переработки второго поколения, разработанную Fiberight, для восстановления экологически чистых ресурсов из отходов.
Этот MRF не только предлагает решение по переработке пластиковых пакетов и пластмасс №3–7, но также извлекает органические вещества и превращает их в биотопливо.Кроме того, загрязненные вторсырья, не попавшие на рынок, восстанавливаются и превращаются в товары для местных рынков.
По словам Гарднера, чтобы получить продукт, пригодный для использования, необходимо иметь систему, которая может разделять различные типы материалов. Из четырех проектов по переработке смешанных отходов, которые SCS реализовала за два года, в каждом используется свой процесс.
Какой бы процесс ни использовался в настоящее время MRF, Гарднер предвидит «большой толчок» для более тонкой сегрегации в будущем, особенно когда он будет включать органические вещества, будь то в коммерческом или жилом масштабе.
По мнению Гезелла, развитие большего числа отечественных заводов и товарных точек поможет сбалансировать влияние внешних рынков. Это также может повлиять на уровень чистоты. «Сохранение отечественных товаров также является хорошим решением проблемы морского пластика».
В связи с постоянным изменением вторсырья необходимо адаптировать оборудование и процессы. Как предполагает Гезелл, время покажет, как нынешнее стремление к отказу от пластика или хотя бы одноразового пластика сформирует MRF будущего. Одно можно сказать наверняка: технология сортировки приспособит
Sorting it All Out — Family Locket
Источники играют жизненно важную роль в генеалогических исследованиях, и качество и количество источников имеют значение.Элизабет Шоун Миллс, известный генеалогический эксперт, объясняет: « источников дают нам информации , из которых мы выбираем свидетельств для анализа. Обоснованным выводом можно считать доказательство »[1]
.
Часть процесса «Исследования как профессионал» заключается в том, чтобы «выкопать свои документы и найти источники в Семейном древе FamilySearch или других онлайн-деревьях, которые относятся к вашему предку. Когда вы собрали все исходные документы, тщательный анализ каждого из них и информации, содержащейся в них, может прояснить то, что вы знаете, и указать вам на следующее направление исследования.”[2]
После того, как вы проверите свою ДНК, у вас появится дополнительный источник, который поможет вам в семейно-историческом исследовании. В контексте использования ДНК в генеалогических исследованиях you — это источник , который дает информацию — в форме ДНК — которая может использоваться в качестве доказательства для поддержки или не поддержки семейных отношений. Информация ДНК должна использоваться в сочетании с генеалогическими записями и известными семейными отношениями; затем он используется в качестве доказательства , чтобы предоставить доказательство родства.
Типы источников
Есть 3 типа источников; оригинальные, производные и авторские рассказы. Человек, который проходит коммерческий ДНК-тест, является первоисточником — источниками высочайшего качества.
— Вы источник.
— Источниками являются ваши родственники.
— Источниками являются еще неизвестные вам люди.
Типы информации
Информация из источников может быть первичной (информация из первых рук), вторичной (информация из вторых рук) или неопределенной.
Первоисточники о людях дают первичной информации в виде результатов тестов ДНК. Если вы посмотрите на фактические необработанные данные вашего ДНК-теста, вы увидите, что они состоят из букв A, T, C и G, которые обозначают нуклеотиды аденин, тимин, цитозин и гуанин.
Компании, такие как AncestryDNA, Family Tree DNA, MyHeritage, 23andMe, LivingDNA и другие, сравнивают информацию о вашей ДНК с информацией о ДНК других людей в своей базе данных.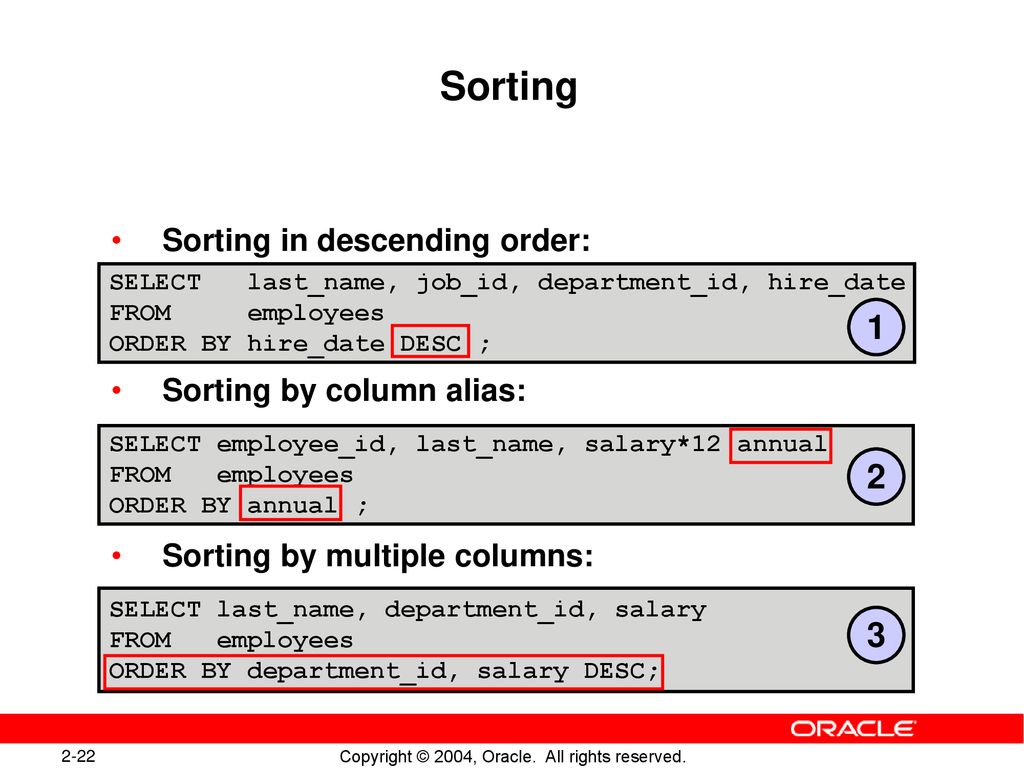 Вам дается список людей, с которыми вы разделяете разное количество ДНК.Этот «список совпадений ДНК» дает вам число в сантиморганах (сМ) или процент от количества ДНК, которое вы разделяете с каждым человеком в вашем списке.
Вам дается список людей, с которыми вы разделяете разное количество ДНК.Этот «список совпадений ДНК» дает вам число в сантиморганах (сМ) или процент от количества ДНК, которое вы разделяете с каждым человеком в вашем списке.
Другие источники: онлайн-генеалогические деревья вашей ДНК соответствуют
Другие источники, используемые в сочетании с ДНК, — это родословные ваших совпадений ДНК. Родословные онлайн можно считать авторскими рассказами . Человек или люди, которые построили каждое дерево, принимали решения о том, какую информацию и документы включить, чтобы установить личности их предков.Информация в дереве может быть верной, но вам все равно нужно будет пройтись по дереву, чтобы убедиться, что информация о семье, содержащаяся в нем, верна. В ходе исследования вам может понадобиться построить деревья для некоторых матчей.
Используйте источники и информацию, чтобы найти общих предков, которые свяжут вас с людьми из вашего списка совпадений ДНК.
Вы ( источник ) и ваша ДНК ( информация ) можете использовать доказательств с по доказательства родства.
Помните, что для того, чтобы ДНК могла быть полезной в генеалогических исследованиях, ее необходимо использовать в сочетании с известными семейными отношениями. Надежные генеалогические исследования и записи, подтверждающие родство, могут быть затем подтверждены ДНК.
ДНК родственника, который относится к определенной линии семьи, может использоваться в качестве доказательства, чтобы помочь доказать, является ли историческое лицо вашим общим биологическим предком или нет. Чем больше у вас информации о ДНК от родственников по определенной семейной линии, тем больше у вас будет доказательств, подтверждающих родство с предками.
Некоторая общая информация, о которой следует помнить:
atDNA: Чем больше количество общей аутосомной ДНК между вами и человеком из вашего списка совпадений = тем ближе родственник.
Y-ДНК: Ваш тест назовет гаплогруппу Y-ДНК и выдаст список людей, которые имеют одинаковое или подобное количество повторов генетического кода в местоположении маркера. Список может содержать несколько человек, у которых очень похожее количество повторов у одних и тех же маркеров.В отчете будет указано число, указывающее на генетическую дистанцию. Чем меньше генетическое расстояние, тем ближе относительное или меньшее количество поколений с тех пор, как произошла мутация или вариация в повторяющемся генетическом коде.
мтДНК или митохондриальная ДНК обнаруживается в митохондриях, которые представляют собой органеллы в клетках человека, которые преобразуют питательные вещества в энергию. Тест мтДНК дает гаплогруппу мтДНК. Эта ДНК и соответствующее название гаплогруппы передаются от матери их детям.Девочки передают мтДНК своим детям. Гаплогруппа мтДНК может использоваться в качестве доказательства того, что потомки биологически связаны с матерью матери, матерью и так далее. Если два человека имеют общую гаплогруппу мтДНК, у них есть общий женский предок.
Если два человека имеют общую гаплогруппу мтДНК, у них есть общий женский предок.
Проанализируйте свои источники
Теперь, когда у вас есть информация о ДНК, семейные деревья в Интернете и генеалогические документы, вы можете проверить свои гипотезы о родстве, задавая вопросы по данным ДНК.На сегодняшний день я нашел лучший ресурс для поиска возможных отношений между вами и вашим родственником в вашем списке совпадений — это инструмент Shared cM Project 3.0 v4 по адресу https://dnapainter.com/tools/sharedcmv4. Спросите себя: «Что из этого совпадения подтверждают семейные отношения, которые я знаю? Соответствуют ли вероятности cM и отношений отношениям на деревьях? » Изучая и анализируя информацию ДНК, вы обретете уверенность в использовании ДНК таким образом.
Составьте таблицу совпадений ДНК
Поскольку авторские повествования в форме генеалогических деревьев могут быстро расширить (и усложнить!) Объем информации, которую необходимо исследовать, полезно иметь возможность эффективно анализировать их. Хороший способ сделать это — применить методы визуализации к имеющейся у вас информации. Нарисуйте диаграмму, чтобы визуализировать людей из вашего списка совпадений ДНК и убедитесь, что они правильно размещены в вашем генеалогическом древе. (См. Мой предыдущий пост о том, как это можно сделать.) Видение общей картины: 3 способа составить график совпадений ДНК Эту информацию также можно ввести в вашу личную генеалогическую программу. Мне нравится использовать Lucidchart.com, потому что я могу включить в список только тех родственников, которые помогут мне с моей исследовательской целью, и я сосредотачиваюсь на людях, внесенных в мои списки совпадений ДНК, и их прямых предках.
Хороший способ сделать это — применить методы визуализации к имеющейся у вас информации. Нарисуйте диаграмму, чтобы визуализировать людей из вашего списка совпадений ДНК и убедитесь, что они правильно размещены в вашем генеалогическом древе. (См. Мой предыдущий пост о том, как это можно сделать.) Видение общей картины: 3 способа составить график совпадений ДНК Эту информацию также можно ввести в вашу личную генеалогическую программу. Мне нравится использовать Lucidchart.com, потому что я могу включить в список только тех родственников, которые помогут мне с моей исследовательской целью, и я сосредотачиваюсь на людях, внесенных в мои списки совпадений ДНК, и их прямых предках.
Я рекомендую вам включать в развернутую диаграмму следующую информацию:
1. Название матча — имя, указанное в аккаунте, а также имя, если вы его знаете
2. Компания, с которой проводилось тестирование, и укажите, находятся ли они на Gedmatch.com
3. Родство или оценка взаимоотношений, если вы все еще не знаете, что делать
4. Количество ДНК, переданных вам или человеку, которому вы помогаете
Количество ДНК, переданных вам или человеку, которому вы помогаете
5. Другая важная информация, которую вы считаете важной
С «Pro» версией Lucidchart.com, вы можете добавить гиперссылку к онлайн-генеалогическому древу матча. Это помогает быстро найти дополнительную информацию в их дереве, которая может помочь в вашем исследовании.
Затем закодируйте формы цветом: используйте один цвет, чтобы указать людей в списке совпадений ДНК, другой цвет, чтобы указать общих предков, и используйте другой цвет, чтобы выделить людей, которых вы ищете.
Наконец, укажите неизвестные или предполагаемые взаимосвязи пунктирной линией на вашем графике.
Продолжайте использовать методы исследования как профессионал, чтобы подтвердить или опровергнуть отношения людей, обозначенных пунктирными линиями на вашем графике.После того, как вы подтвердите родство в одной семейной линии, повторите процесс для других семейных линий, чтобы исследовать и подтвердить родственные связи в вашем генеалогическом древе. Скоро вы будете знать больше, чем когда-либо прежде, исследуя ДНК как профессионал!
Скоро вы будете знать больше, чем когда-либо прежде, исследуя ДНК как профессионал!
[1] Элизабет Шоун Миллс, «Основы анализа доказательств», Объяснение доказательств: цитирование исторических источников от артефактов до киберпространства, 3 -е издание , исправленное, (Балтимор, Мэриленд: Genealogical Publishing Company, Inc., 2017), 15-38, в частности 24.
[2] Дайана Элдер, AG с Николь Дайер, «Анализируйте свои источники», Research Like a Pro: A Genealogist’s Guide , (Highland, Utah: Family Locket Books, 2018), 19-29, в частности 19.
Другие статьи из серии «Исследования как профессионал с ДНК»:
Шаг 1 Пройдите тест ДНК: какой тест ДНК мне следует пройти? и стратегия тестирования, рекомендованная ДНК
Шаг 2 Оценка: понимание и использование результатов вашей ДНК — 4 простых шага
Шаг 3 Организация: видение общей картины: 3 способа определения совпадений ДНК
Шаг 4 Цель исследования: что вы хотите знать ? 3 шага, чтобы сфокусировать свое исследование ДНК
Шаг 5 Проанализируйте свои источники: источники ДНК, информация и свидетельства: разберитесь со всем — Вы здесь
Шаг 6 Исследование местности: куда попала моя ДНК? ДНК и исследование местности
Шаг 7 Планирование исследования: Планирование генеалогических исследований с использованием ДНК
Методология и инструменты для использования при планировании исследования:
— Диаграммы для понимания наследования ДНК
— Кластеризация или создание генетических сетей
— Триангуляция родословной
— Браузеры хромосом
— Сегментная триангуляция
— Картирование хромосом
— ДНК Gedcom
Шаг 8 Цитирование источников: Цитирование источников ДНК
Шаг 9 Журналы исследований: Журналы исследований ДНК: как отслеживать генетические генеалогические поиски
Шаг 10 Составление отчета: отчеты об исследованиях ДНК — окончательный Finish
Шаг 11 Что дальше? Продолжайте исследования и писать, продуктивность и образование
Сохранить в Pinterest:
Нравится:
Нравится Загрузка. ..
..
Связанные
Джим Хоппер, PH.D. | Самостоятельная сортировка
Очень важно то, как люди определяют свой собственный опыт, и ярлыки, которые они им дают (или не дают).
Меня не интересует навешивание ярлыков на кого-либо или даже определение «сексуального насилия» или чего-либо еще. Для моих целей это не нужно и не полезно.
Мне не нужно навешивать на вас ярлыки.
Вместо этого я предлагаю инструментов для размышлений о детском или подростковом сексуальном опыте, который мог вызвать или способствовать возникновению текущих проблем.
Но я не могу избежать слов
Конечно, мне пришлось выбрать или слово. Я остановился на « нежелательных или оскорбительных сексуальных опытах в детстве».
Вот как я на этом сайте ссылаюсь на детские и юношеские сексуальные опыты, которые могут вызвать множество проблем даже во взрослой жизни.
Мои слова тщательно подобраны, потому что я стремлюсь:
- Уважать опыта и точки зрения каждого человека.
- Избегайте любых определений или ярлыков, которые могут отпугнуть любого человека , который мог бы использовать этот сайт, чтобы разобраться в своем собственном уникальном опыте и возможностях.
Я также хочу подчеркнуть, что означает «нежелательный или оскорбительный сексуальный опыт в детстве» , а не …
Под «нежелательным» я не имею в виду, что опыт должен был быть нежелательным , когда это произошло. Например, ребенок может чувствовать, что он или она хочет сексуального контакта со взрослым (особенно, если взрослый манипулировал ребенком).Вместо этого, когда я говорю «нежелательный», я имею в виду:
- Оглядываясь назад, неужели вы хотите пережить этот опыт, стать частью своей жизни?
- Хотите ли вы иметь негативные мысли, чувства и поведение, которые, оглядываясь назад, вы подозреваете или считаете (по крайней мере, частично) вызванными этим опытом?
«Как этот опыт повлиял на меня?»
Кроме того, «или» в слове «нежелательный или оскорбительный» не означает, что не означает, что любой нежелательный сексуальный опыт также был «оскорбительным».«Я не верю, что это правда. Я просто надеюсь, что «нежелательное» работает достаточно хорошо, когда речь идет об описании детского или подросткового сексуального опыта, который, возможно, способствовал возникновению у вас проблем. (Или, по крайней мере, недостаточно, чтобы вас оттолкнуть.)
Инструменты для самостоятельной разборки
Для некоторых из вас именно поэтому вы здесь прямо сейчас. Вы пытаетесь разобраться на своих условиях:
- «О чем на самом деле был этот детский (или юношеский) сексуальный опыт ?»
- «Как повлиял на меня тем опытом?»
- «Является ли и причиной того, что я борюсь с _____ ?»
Вопрос: «О чем на самом деле был этот сексуальный опыт?» может быть самым простым, и может потребоваться время, чтобы разобраться.Это подразумевает другие вопросы, например:
- Был ли другой человек в положении власти или власти надо мной?
- Был ли я манипулировал , заставляя заниматься сексом или полагая, что я хочу этого, даже когда на самом деле этого не делал?
- Изменила ли сексуальная активность то, что было положительными отношениями, на отношения секретности и стыда ?
- Был ли другой человек использовал меня, не учитывая мой опыт или мои потребности?
- Воспользовался ли другой человек уязвимостями , которые были у меня в то время, — чувствовал себя изолированным и одиноким, возбужденным и любопытным, но не знающим о сексе?
Речь идет о вашем опыте, ваших возможностях, жизни, которую вы хотите .
Эти вопросы говорят о возможной эксплуатации, предательстве и пренебрежении к вашему благополучию — опыте, который может вызвать множество проблем сразу и во взрослой жизни.
Кроме того, эти вопросы относятся к опыту общения с другими детьми или подростками, а не только со взрослыми. Независимо от того, сколько лет было другому человеку, если бы речь шла о доминировании, манипулировании, эксплуатации, предательстве или пренебрежении к вашему благополучию, переживания, возможно, способствовали возникновению проблем в вашей жизни сейчас.
Важно: Идея здесь , а не , чтобы подтолкнуть кого-либо осудить или даже навесить ярлык на другого человека или людей, которые тоже могли быть хорошими по отношению к вам и которые могут вам все еще нравиться, даже любить. Кроме того, такие переживания могли включать в себя внимание, привязанность и физические ощущения, которые в то время вы находили приятными и в некотором роде желанными (например, неуверенно смешанными со стыдом).
Смысл попытки «разобраться во всем», если вы решите это сделать, состоит в том, чтобы понять, помогли ли — и если да, то почему и как — сексуальный опыт (я) вызвать некоторые проблемы, которые у вас есть сейчас ( например, проблемы со стыдом, гневом, зависимостью или депрессией).
Подводя итог, на этом веб-сайте я предоставляю ресурсы для того, чтобы разобраться, что случилось с , вы, , что имеет смысл с , вы, , и варианты, как справиться с вашим уникальным опытом и приблизиться к жизни вы хотите.
Что такое сортировка данных? | Примеры сортировки данных
Сортировка данных — это любой процесс, который включает в себя упорядочивание данных в некотором значимом порядке для облегчения понимания, анализа или визуализации.При работе с данными исследования сортировка — это распространенный метод, используемый для визуализации данных в форме, упрощающей понимание истории, которую они рассказывают. Сортировка может выполняться по необработанным данным (по всем записям) или на агрегированном уровне (в таблице, диаграмме или другом агрегированном или сводном выводе).
Данные обычно сортируются на основе фактических значений, счетчиков или процентов, в возрастающем или убывающем порядке, но также могут быть отсортированы на основе меток значений переменных. Метки значений — это метаданные, имеющиеся в некоторых программах, которые позволяют исследователю сохранять метки для каждого варианта значения категориального вопроса.Большинство программных приложений также позволяют выполнять сортировку по нескольким переменным. Этот тип сортировки будет выполняться с заранее определенным переменным приоритетом, например, набор данных, содержащий поля региона и страны, может быть сначала отсортирован по региону в качестве основной сортировки, а затем по стране. Сортировка по округам будет применяться в каждом отсортированном регионе.
Простой пример
Чтобы проиллюстрировать базовую операцию сортировки, рассмотрим приведенную ниже таблицу с двумя столбцами: Страна и Население .Столбец Country представляет собой текстовое поле (или метку), тогда как столбец Population содержит числовые данные. В таблице слева показаны исходные данные, которые не отсортированы в каком-либо определенном порядке. Таблица справа отсортирована по Населению в порядке убывания. Другими словами, страна с наибольшим населением помещается в первую строку, за ней следует страна со вторым по численности населения и так далее.
Это позволяет читателю легко понять порядок стран без необходимости сравнивать все числа в таблице.
Стандартные приложения
Существует несколько стандартных приложений для сортировки при работе с любыми типами данных. Одним из таких приложений является очистка данных, которая представляет собой процесс сортировки данных для поиска отклонений в шаблоне данных. Например, данные о продажах за месяц можно отсортировать по месяцам, чтобы найти отклонения в объеме продаж.
Другое распространенное использование сортировки — ранжирование или приоритезация записей. В этой ситуации данные сортируются по некоторому рангу, расчетному баллу или другому значению приоритета (например, учетные записи с наибольшим объемом или клиенты с интенсивным использованием).
Правильная сортировка визуализаций (таблиц, диаграмм и т. Д.) Также чрезвычайно важна для правильной интерпретации данных. Например, в маркетинговых исследованиях обычно сортируют результаты одного вопроса с ответом по процентной доле столбца, то есть от наиболее ответивших до наименее ответивших в порядке убывания, как показано в следующем вопросе о предпочтениях бренда.
Однако нет особого смысла сортировать вопросы по шкале таким же образом. В этих случаях лучше выполнять сортировку по шкале вопросов, поскольку это значительно упрощает задачу интерпретации данных.
Неправильная сортировка часто может привести к неправильной интерпретации. Желательно всегда обеспечивать применение наиболее логичных сортировок ко всем визуализациям.
Технические проблемы
Несмотря на то, что применение функций сортировки — простая для понимания концепция, есть несколько технических проблем, о которых следует знать. Одна из таких проблем — произвольная сортировка неуникальных данных. В качестве примера снова предположим, что у вас есть набор данных с полями региона и страны и несколькими записями для каждого региона.Если применяется сортировка по региону, какая будет вторичная сортировка по умолчанию? Другими словами, как будут сортироваться данные в каждом регионе?
Это зависит от приложения. Например, Excel сохранит исходную сортировку в качестве порядка сортировки по умолчанию после выполнения основной сортировки. Базы данных SQL не имеют порядка сортировки по умолчанию. Скорее это зависит от других факторов, таких как используемая система управления базами данных (dbms), индексы и другие факторы. Другие приложения могут применять дополнительную сортировку по умолчанию в зависимости от порядка столбцов.
Другая потенциальная проблема — сортировка числовых данных при хранении в текстовом поле. В этом случае числа будут отсортированы в алфавитно-цифровом порядке, а не в числовом. Например, рассмотрим следующий набор числовых значений: (12, 4, 1, 31,18, 101). При числовой сортировке они будут возвращены в числовом порядке по возрастанию: (1, 4, 12, 18, 31, 101). Однако, если эти значения хранятся в текстовом поле и отсортированы в порядке возрастания, будет возвращена следующая сортировка: (1, 101, 12, 18, 31, 4).Это также проблема при сохранении значений даты в текстовых полях.
Программное обеспечение
Большинство пакетов программного обеспечения для анализа и статистики предоставляют широкий спектр функций сортировки практически на каждом этапе обработки данных.
| Приложение | Доступные методы сортировки |
| Q | Примените пользовательскую сортировку к выходным данным таблицы, необработанным данным или с помощью QScript для автоматизации функций сортировки. |
| R | Применение функций сортировки к различным объектам с разными структурами данных (векторам, фреймам данных, матрицам и т. Д.) |
| Дисплей | Сортировка выходных данных таблицы и применение пользовательской сортировки к функциям R |
| SPSS | Сортировка выходных данных таблицы или использование синтаксиса для применения сортировки к объектам |
| SQL | Использует предложение ORDER BY для сортировки набора записей при выполнении операторов SQL |
Подпишитесь на Displayr
По мере того как пандемия продолжается, Burloak Theater Group «разбирается с этим»
Burloak Theater Group, одна из трех основных театральных трупп Оквилля, открывает сезон 2021 года сегодня вечером с Sorting it Out , новой пьесы местного драматурга Маттео Эспозито.
Это первая презентация в «сезоне новых работ», и, поскольку пандемия продолжает задерживать возвращение развлекательных программ, она будет представлена в Интернете и будет транслироваться бесплатно как на Facebook, так и на YouTube.
Но назначить премьеру сегодня вечером не случайно: 27 марта — Всемирный день театра, поэтому сегодня был идеальный выбор для дебюта спектакля. И для Эспозито это был долгий путь: он работал над получасовым спектаклем почти четыре года.
«Спектакль начался как настоящий опыт в автобусе, — говорит Эспозито, — и это взаимодействие с другим человеком стало спектаклем.«Эспозито страдает аутизмом, и это было в 2017 году, когда он имел негативный опыт, о котором говорили, когда он ехал в городском автобусе; такое случается слишком часто».
Маттео продолжает: «Я сказал:« С меня достаточно этих людей ». Я хотел создать историю об этом». Именно это он и сделал.
Перенесемся на несколько лет вперед, и с тех пор Маттео оттачивает и совершенствует свою игру на нескольких площадках. Он выступал с частными выступлениями для групп в городе, работал с ними в Barrie Theater Lab, а также имел небольшую пробу в St.Средняя школа Фомы Аквинского в 2019 году.
«Поначалу пьеса была более противоречивой, — говорит Эспозито. «Но теперь он стал более плотным и собранным. Видеть его, конечный продукт в Оквилле, действительно приятно. Я горжусь тем, что вижу его в полноценном продукте».
Что касается конечного продукта, то постановка Burloak (открывающая цифровой сезон новых пьес 2021 года) принесет Sorting it Out самой широкой аудитории. И Эспозито, и режиссер шоу встретились с Oakville News, чтобы обсудить проект.
Президент Burloak Тим Кадени сам руководит шоу, работая с Маттео, когда он начал волонтерство в компании в прошлом году. Об этой пьесе Кадени говорит: «Это пронзительная пьеса страстного драматурга». И он прав — если у Эспозито больше ничего нет, у него есть страсть.
«Мы всегда ищем новый материал и новые работы», — говорит Кадени. «Мы подумали, что это будет действительно хорошая возможность для нашего виртуального сезона, и Маттео великолепно внес изменения в сеттинг.«
О том, что привлекло его к этой пьесе, Кадени продолжает, что Эспозито «написал несколько интересных трехмерных человеческих персонажей. Мы указали, кто они такие, понимая, что это шоу в стиле Zoom». Как режиссер он добавил зеленые экраны и фоны, чтобы добавить театральности образу.
После того, как виртуальное шоу закончится в эти выходные, Sorting It Out ждет еще больше жизни. Эспозито ведет переговоры о переносе шоу в место проведения вне Бродвея в Нью-Йорке, возможно, уже осенью 2021 года.Для этого шоу он также будет художником-декоратором (который в настоящее время учится в Шеридан-колледже по программе технического театра).
Но энергичность и решимость Эспозито рассказать свою историю — вот что делает его игру наиболее увлекательной. Так что он надеется, что люди вынесут из спектакля?
«Это послание инклюзивности или честно, — говорит он, — сообщение о том, что книгу нельзя судить по ее обложке. Я думаю, что люди заберут эти послания с собой домой».
Sorting it Out представляет Burloak Theater Group бесплатно в эти выходные на YouTube и Facebook Live.Шоу в 19:30. сегодня вечером, в субботу, 27 марта 2021 г. и в 14:00 завтра, воскресенье, 28 марта.
Несмотря на то, что спектакль предоставляется всем бесплатно, Burloak Theater Group также с радостью принимает пожертвования на свою работу, чтобы покрыть расходы на производство. Вы можете сделать им пожертвование здесь.
Тайлер Коллинз
Тайлер Коллинз — помощник издателя Oakville News и репортер по искусству. Он начал с новостей в 2016 году и теперь специализируется на текущих и живых событиях, кино, театре и развлечениях.
Подробнее Тайлер Коллинз
27 марта 2021 г.
10:00
Если бы каждый мог разобраться, как Маттео Эспозито
Маттео Эспозито хочет дать публике повод для размышлений.
Его новая пьеса «Разбираясь» основана на личном опыте и исследует мир аутизма через конкретное событие. Подробнее об этом позже.
Эспозито из Оквилля, 23 года, хорошо функционирующий аутичный мужчина, стремящийся добиться успеха в театральном сообществе.В настоящее время он изучает технический театр в Sheridan College, а его пьеса «Sorting It Out» уже привлекла внимание BurlOak Theater, общественной компании, которая продюсирует ее в рамках предстоящего виртуального сезона.
Это также было прочитано Джоном Пикоком и его группой Play Reading With Friends в Нью-Йорке. Ходят слухи, что они подумывают об экскурсии по старшим школам Нью-Йорка.
Эти утверждения придали Эспозито смелость и воодушевление, чтобы продолжить его поиски жизни в театре.
«Моя текущая игра — это настоящий удар по стене», — говорит он. «Это честно и потрясающе. Он говорит о том, что значит быть аутичным и игнорироваться или неправильно пониматься многими людьми. Речь идет об опыте, который я испытал в автобусе, когда кто-то жестоко обращался с инвалидом », — говорит он. «Это смотрит на то, как невежество может быть причиной таких событий. Пьеса, конечно, развлекательная, но также поучительная и познавательная, побуждая зрителей самостоятельно разбираться в том, что означает аутизм.Это действительно о расширении границ ».
Эспозито закончил среднюю школу в Сент-Игнатий де Лойола в Оквилле, но у него не было идеального опыта. Как бы то ни было, он добился успеха в Шеридан-колледже, изучая технические аспекты театрального производства.
Его пьеса об аутизме была поставлена в 2019 году с участием уважаемых актеров общественного театра. Это успешное производство привело к появлению виртуальной версии BurlOak.
Эспозито говорит, что работал за кулисами, создавая реквизит для спектакля «Странная парочка» в BurlOak Theater, когда его пьеса рассматривалась для постановки.
«Это вселило в меня большую уверенность. Это заставило меня подумать, что, возможно, я смогу изменить восприятие использования аутичных людей в театральных постановках. Тебе просто нужно выбраться отсюда. Вы должны заставить вещи происходить. Независимо от того, есть ли у вас особые потребности или нет, вы должны работать, чтобы все произошло. Ты не можешь просто сидеть на диване и мечтать «.
У него заботливые родители и хорошие друзья, но не все в его мире идеально.
«Я не люблю инвалидность. И мне не нравятся некоторые из моих поступков, связанных с этим.Но я просто имею дело с колодой карт, которые мне выдали », — говорит он. «Я не боюсь рассказывать людям о своем аутизме. В моей жизни есть прекрасные люди, которые любят меня до смерти. Мое послание другим: «Не бойтесь меня, потому что я другой».
Сообщения в пьесе Эспозито также отражают это. Они написаны крупно и четко, и правильно полагают, что это будет отличная пьеса для выступления в школе. Да, это проблемная игра, но в ней проявляются забота и сочувствие.
«Sorting It Out» состоит из четырех человек. Один из актеров страдает аутизмом.
«Это то, что я очень сильно люблю», — говорит Эспозито. «Я хочу, чтобы больше театральных трупп использовали людей с ограниченными возможностями в своих постановках. Всем важно видеть себя на сцене ».
Эспозито надеется стать сценографом для театра и продолжать писать пьесы, имеющие значение.
«Я знаю, что я не Дэвид Мамет, но чувствую, что могу создать что-то особенное. Просто дайте мне шанс.”
Загрузка …
Загрузка … Загрузка … Загрузка … Загрузка … Загрузка …
Маттео Эспозито
What: Sorting It Out
Где: Virtual production from BurlOak Театр
Когда: 27-28 марта в 14.00 и 19.30
Информация: Бесплатное представление. Перейдите на сайт botg.ca/sorting- it-out
Разбираем — FDA AdComm Review за 2019
У FDA достаточно рекламных сообщений? В прошлом году было одобрено большое количество лекарств, но не произошло соответствующего увеличения числа консультативных комитетов, организованных FDA.В конце 2019 года у меня был пост о том, что похоже, что FDA приближается к году, когда у него будет меньше консультативных комитетов FDA, чем в прошлые годы. Однако это было преждевременно. FDA удалось пропустить еще несколько встреч в декабре и довести общую сумму, хотя она все еще была намного меньше количества встреч, проведенных в течение многих лет с 2012 по 2019 год.
Подробнее об объеме встреч чуть ниже. Сначала давайте посмотрим, что было удержано — что они считали и каковы были результаты.Сколько собраний человек, сколько об одобрении лекарств и как часто FDA согласовывало с комитетами — и многое другое…
- В течение 2019 календарного года было проведено в общей сложности 28 встреч
- Из 28 встреч 23 были проведены для рассмотрения утверждения лекарства, семь из которых были sNDA или sBLA, а остальное составляли NDA или BLA — остальные пять встречи были для обсуждения конкретных вопросов безопасности или вопросов политики
- Из 23 встреч NDA / BLA / sNDA / sBLA комитеты рекомендовали одобрение 17 лекарств, не рекомендовали одобрение 5 и одно совещание было отменено;
- Из 17 препаратов, одобренных Консультативными комитетами в течение 2019 года, FDA одобрило 12 из них; однако три из них, получившие одобрение комитета, были случаями, когда FDA принимало решение против рекомендации комитета и не одобряло заявку; и есть два заявления, решение по которым не объявлено;
- Фактически, было всего 4 примера того, что FDA противоречит рекомендации комитета — 3, когда FDA отказалось утвердить против рекомендации (упомянутой выше), и 1, когда FDA одобрило препарат, несмотря на рекомендацию комитета против одобрения. — это означало бы, что FDA не соглашалось с рекомендацией Консультативного комитета чуть более 14 процентов времени
- Четыре заседания включали совместные заседания с Комитетом по управлению рисками безопасности лекарственных средств, только на одном из которых рассматривалось NDA для нового продукта
- Чаще всего собирался комитет, как и в 2018 году: Консультативный комитет по онкологическим препаратам собирался шесть раз в этом году, хотя в прошлом году их было девять; следующий по величине уровень активности также был таким же, как и в прошлом году — Консультативный комитет по противомикробным препаратам собирался пять раз (три из которых касались продуктов) по сравнению с шестью заседаниями в прошлом году.
Помимо проведения еще нескольких встреч в конце года, FDA одобрило ряд новых молекулярных образований в последние недели 2019 года и, по сути, быстрее одобряет лекарства, что и было целью изменений в политике. сделано Конгрессом. Кроме того, в последнее время возникают некоторые вопросы относительно более высокого количества новых разрешений по сравнению с меньшим количеством проведенных консультативных совещаний FDA.